
MemOCR: Layout-Aware Visual Memory for Efficient Long-Horizon Reasoning
Paper
• 2601.21468 • Published
• 25
![]()
![]()
MemOCR is a visual memory agent that dynamically adapts information density during memory drafting and reading, and optimizes visual layouts to highlight key information.
This checkpoint is fine-tuned from Qwen2.5-VL-7B-Instruct with budget-aware training objectives.
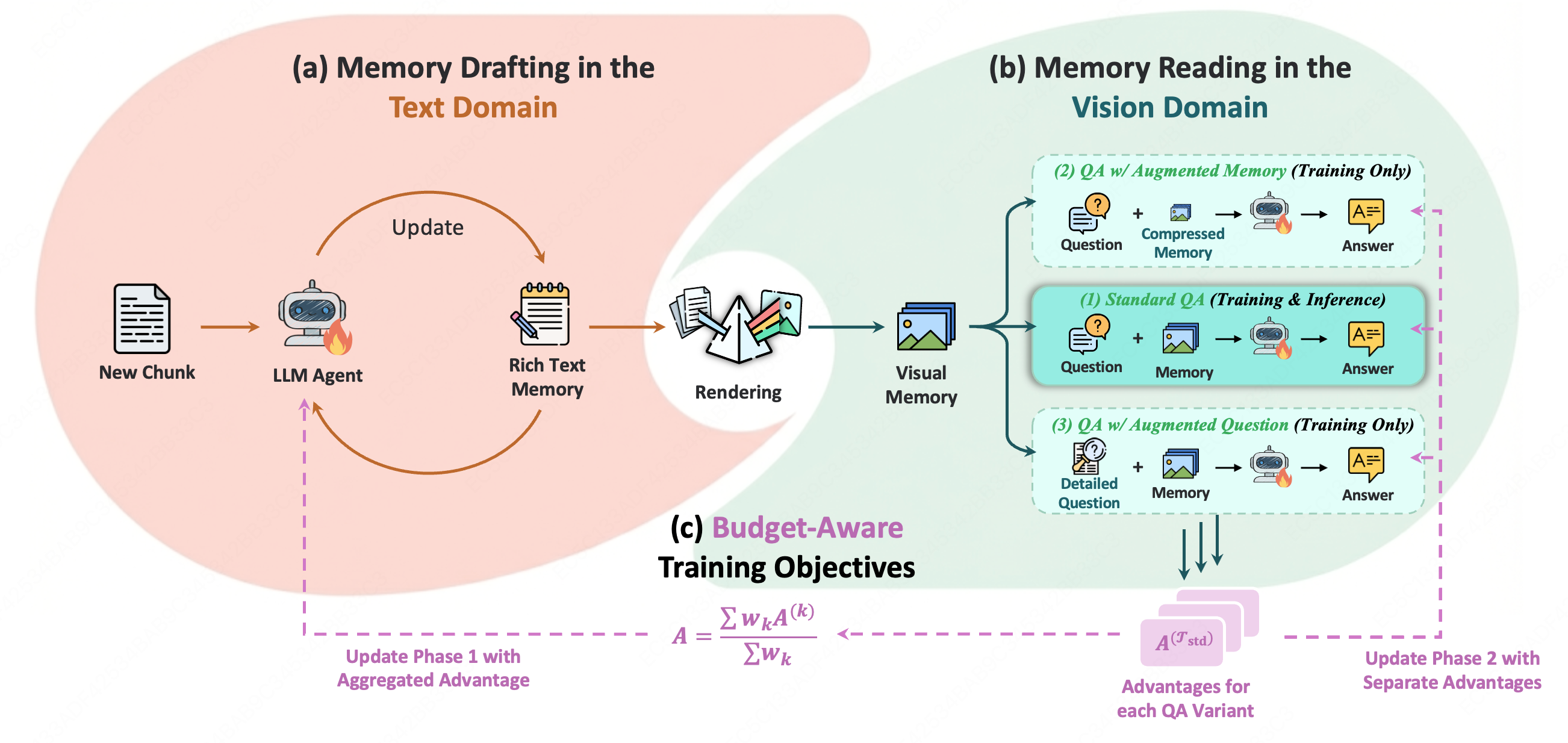
MemOCR consists of two main components:
The framework employs budget-aware training objectives to balance memory informativeness and token efficiency.
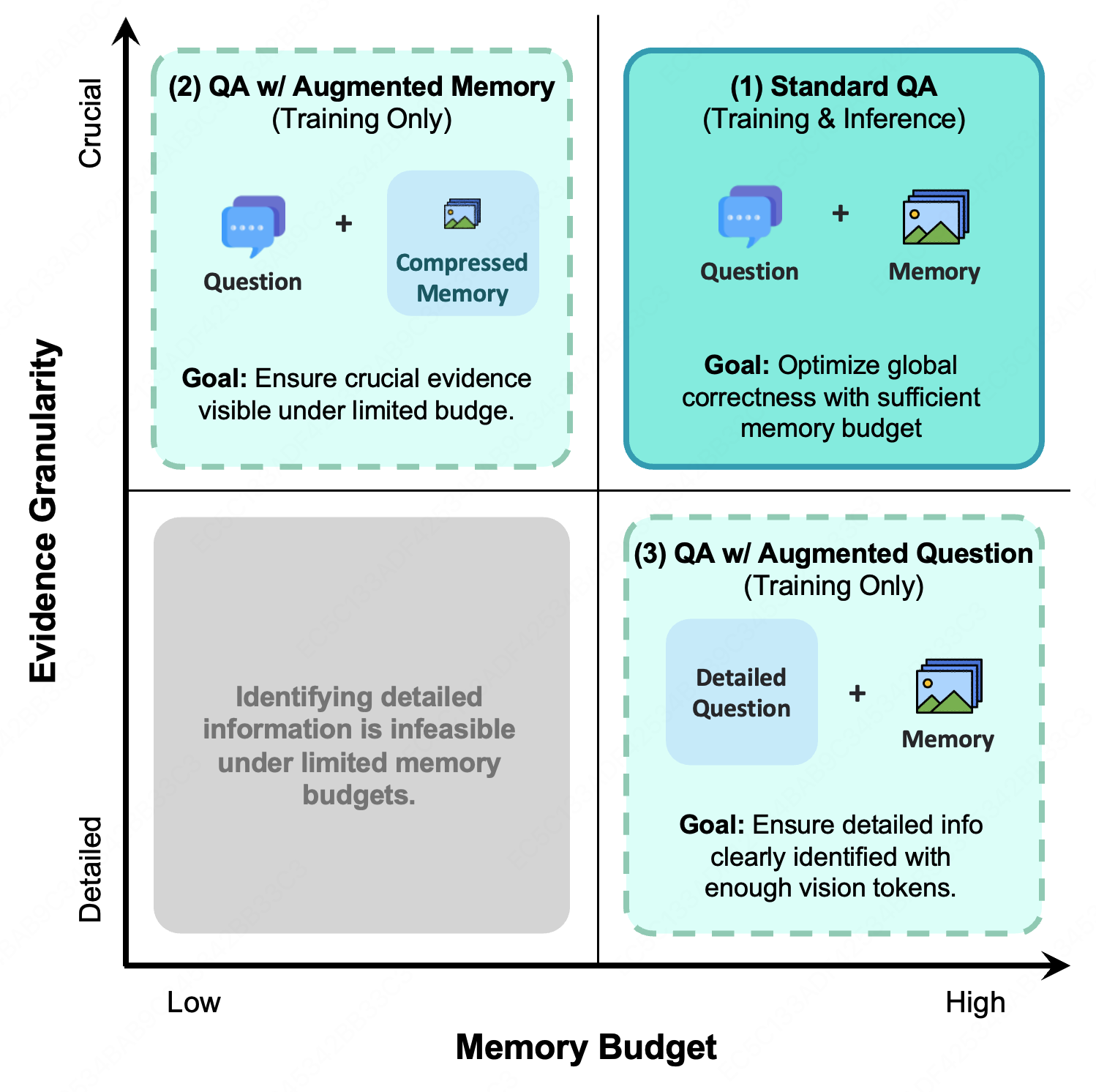
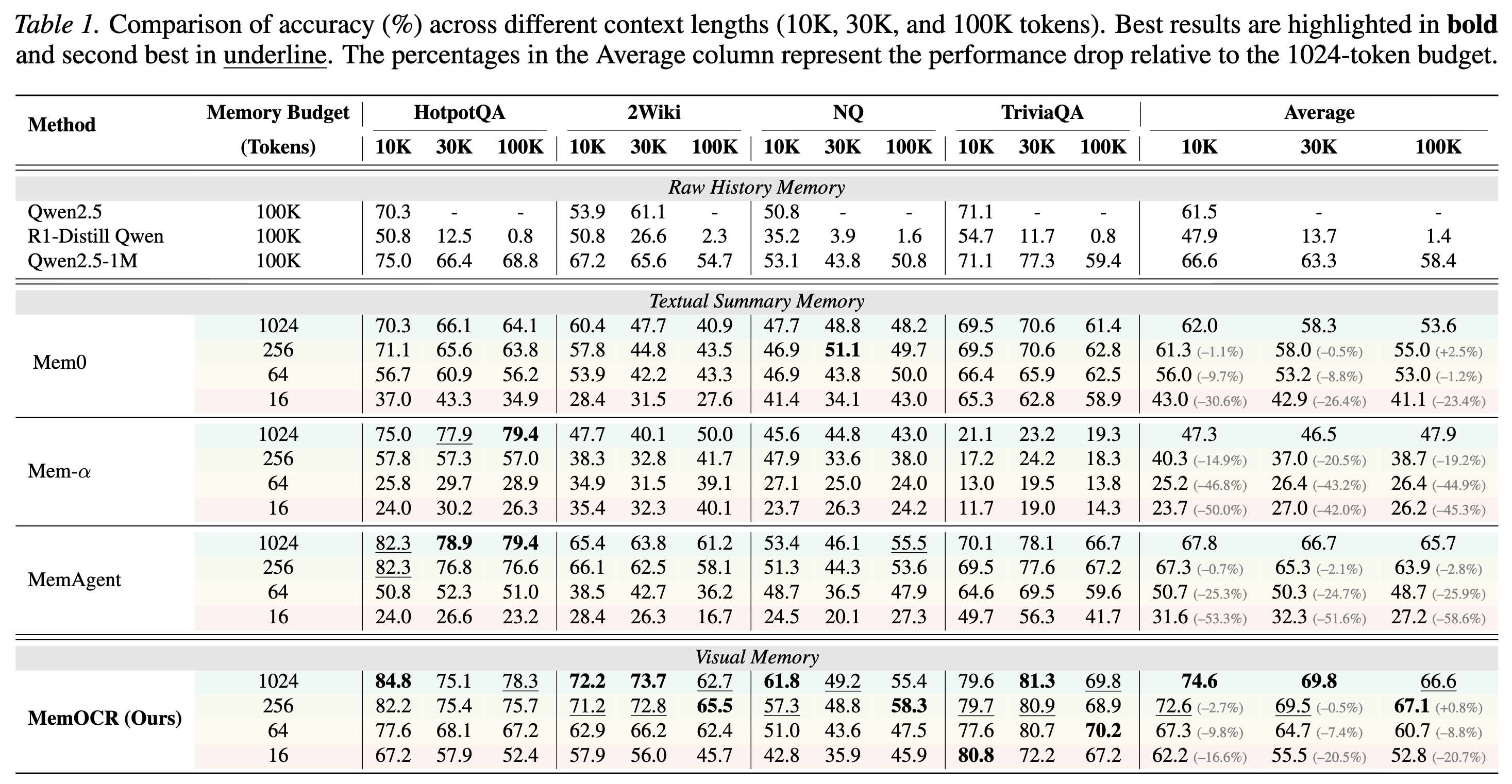
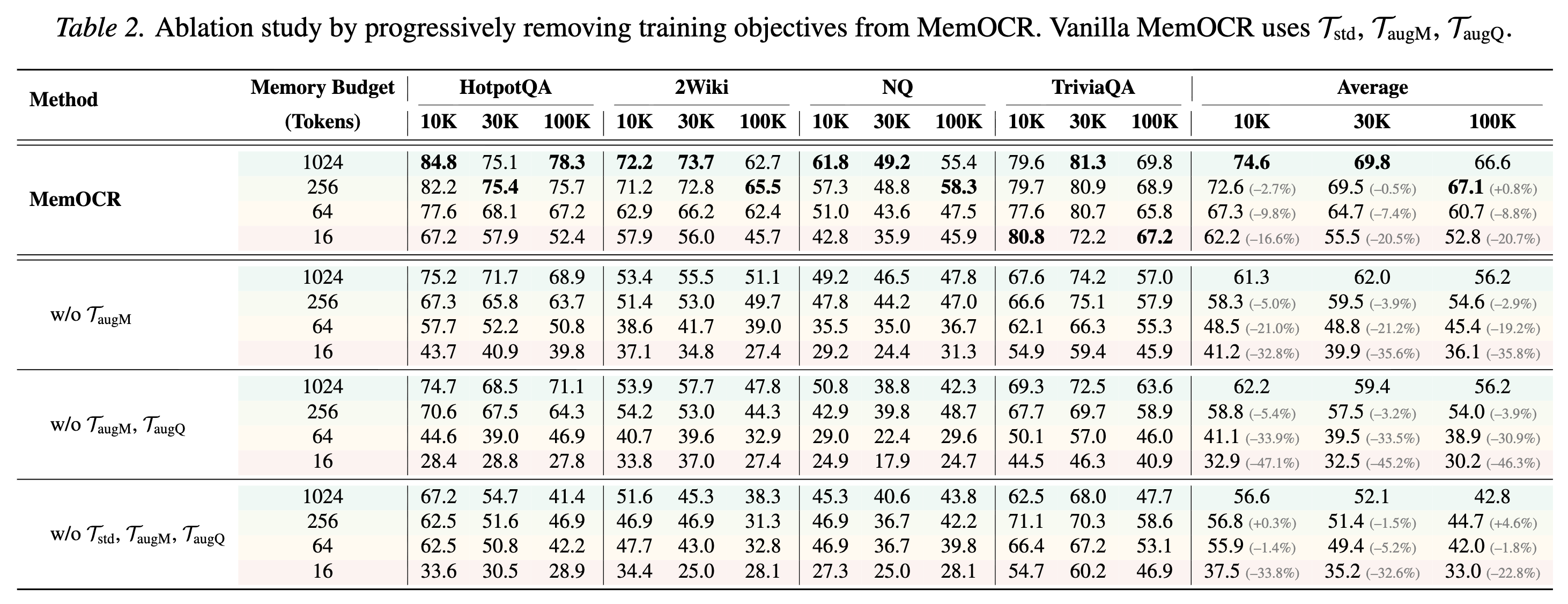
MemOCR achieves state-of-the-art performance across multiple multi-hop QA benchmarks:
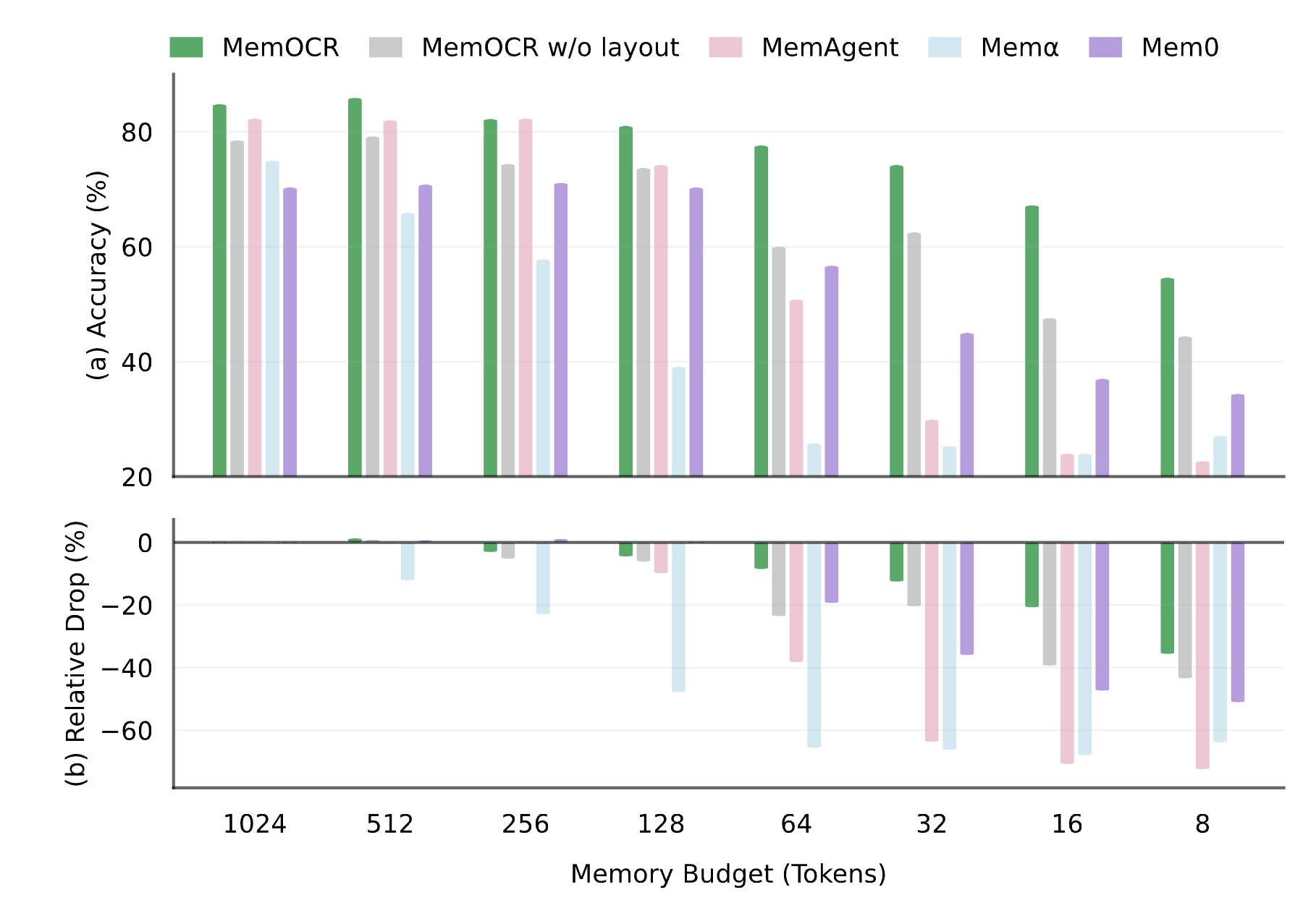
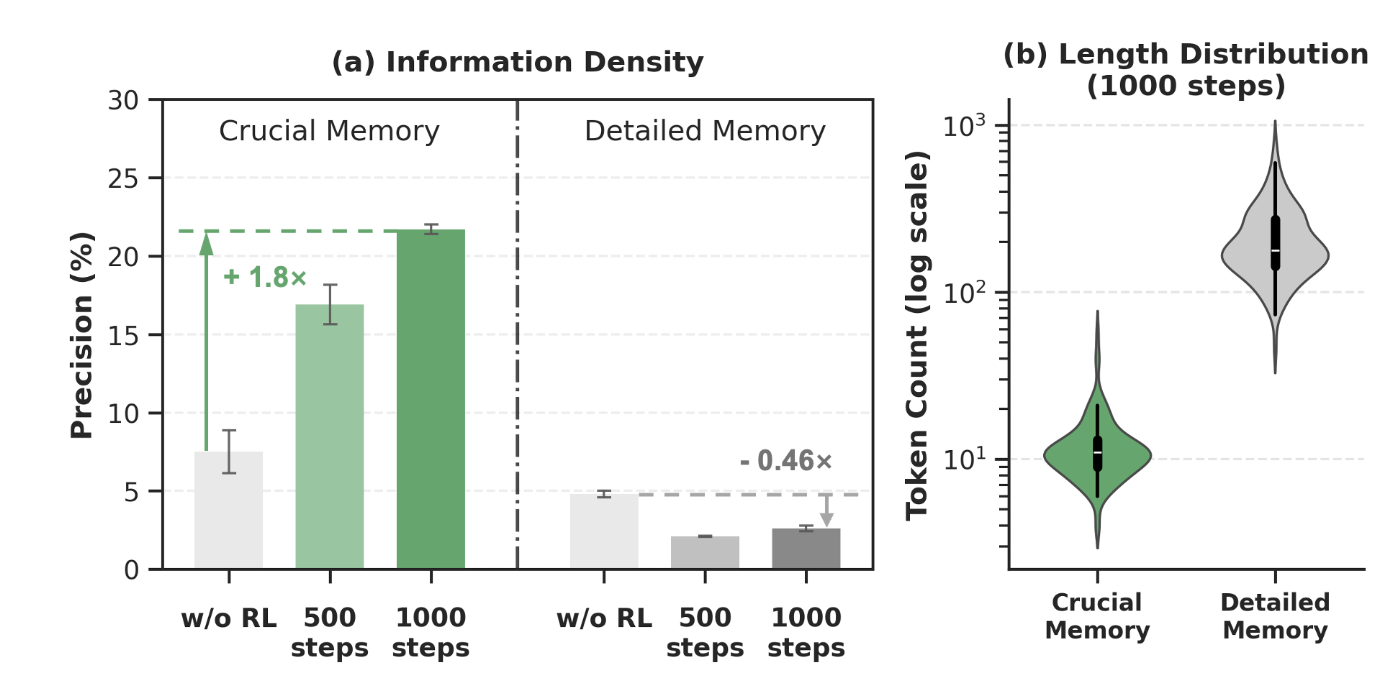
This model is designed to work with the MemOCR framework. Please refer to the official repository for detailed usage instructions.
If you find MemOCR useful in your research, please consider citing:
@article{shi2026memocr,
title={MemOCR: Layout-Aware Visual Memory for Efficient Long-Horizon Reasoning},
author={Yaorui Shi and Shugui Liu and Yu Yang and Wenyu Mao and Yuxin Chen and Qi GU and Hui Su and Xunliang Cai and Xiang Wang and An Zhang},
journal={arXiv preprint arXiv:2601.21468},
year={2026},
}
This model is built upon:
This model is licensed under the Apache License 2.0. See the LICENSE file for details.
Training and evaluation datasets are derived from: