
id int64 599M 2.47B | url stringlengths 58 61 | repository_url stringclasses 1 value | events_url stringlengths 65 68 | labels listlengths 0 4 | active_lock_reason null | updated_at stringlengths 20 20 | assignees listlengths 0 4 | html_url stringlengths 46 51 | author_association stringclasses 4 values | state_reason stringclasses 3 values | draft bool 2 classes | milestone dict | comments sequencelengths 0 30 | title stringlengths 1 290 | reactions dict | node_id stringlengths 18 32 | pull_request dict | created_at stringlengths 20 20 | comments_url stringlengths 67 70 | body stringlengths 0 228k ⌀ | user dict | labels_url stringlengths 72 75 | timeline_url stringlengths 67 70 | state stringclasses 2 values | locked bool 1 class | number int64 1 7.11k | performed_via_github_app null | closed_at stringlengths 20 20 ⌀ | assignee dict | is_pull_request bool 2 classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2,473,367,848 | https://api.github.com/repos/huggingface/datasets/issues/7109 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7109/events | [] | null | 2024-08-19T13:29:12Z | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | https://github.com/huggingface/datasets/issues/7109 | MEMBER | null | null | null | [] | ConnectionError for gated datasets and unauthenticated users | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7109/reactions"
} | I_kwDODunzps6TbJko | null | 2024-08-19T13:27:45Z | https://api.github.com/repos/huggingface/datasets/issues/7109/comments | Since the Hub returns dataset info for gated datasets and unauthenticated users, there is dead code: https://github.com/huggingface/datasets/blob/98fdc9e78e6d057ca66e58a37f49d6618aab8130/src/datasets/load.py#L1846-L1852
We should remove the dead code and properly handle this case: currently we are raising a `ConnectionError` instead of a `DatasetNotFoundError` (as before).
See:
- https://github.com/huggingface/dataset-viewer/issues/3025
- https://github.com/huggingface/huggingface_hub/issues/2457 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | https://api.github.com/repos/huggingface/datasets/issues/7109/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7109/timeline | open | false | 7,109 | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | false |
2,470,665,327 | https://api.github.com/repos/huggingface/datasets/issues/7108 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7108/events | [] | null | 2024-08-19T13:21:12Z | [] | https://github.com/huggingface/datasets/issues/7108 | NONE | completed | null | null | [
"I don't reproduce, I was able to create a new repo: https://huggingface.co/datasets/severo/reproduce-datasets-issues-7108. Can you confirm it's still broken?",
"I have just tried again.\r\n\r\nFirefox: The `Create dataset` doesn't work. It has worked in the past. It's my preferred browser.\r\n\r\nChrome: The `Cr... | website broken: Create a new dataset repository, doesn't create a new repo in Firefox | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7108/reactions"
} | I_kwDODunzps6TQ1xv | null | 2024-08-16T17:23:00Z | https://api.github.com/repos/huggingface/datasets/issues/7108/comments | ### Describe the bug
This issue is also reported here:
https://discuss.huggingface.co/t/create-a-new-dataset-repository-broken-page/102644
This page is broken.
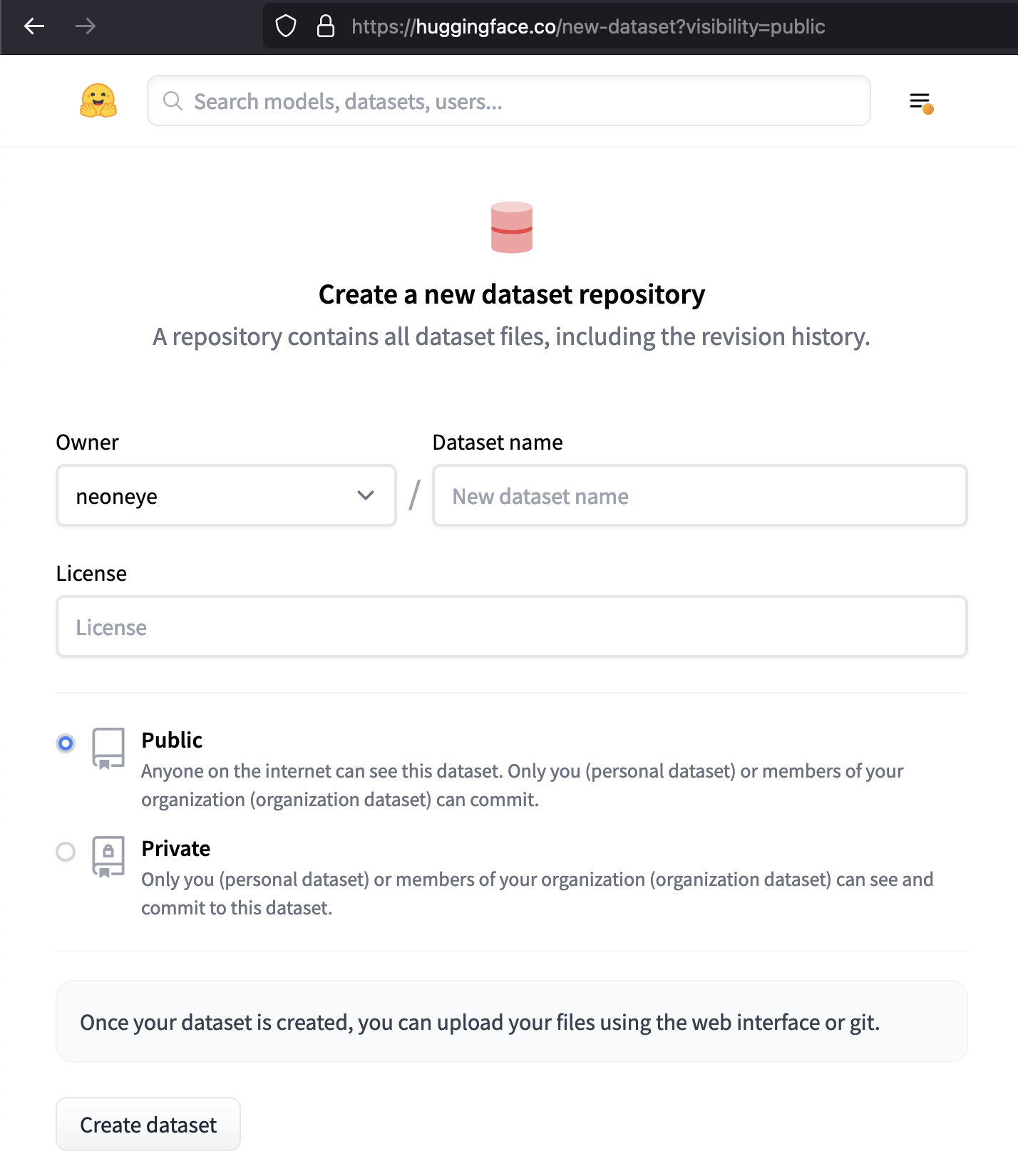
https://huggingface.co/new-dataset
I fill in the form with my text, and click `Create Dataset`.

Then the form gets wiped. And no repo got created. No error message visible in the developer console.
# Idea for improvement
For better UX, if the repo cannot be created, then show an error message, that something went wrong.
# Work around, that works for me
```python
from huggingface_hub import HfApi, HfFolder
repo_id = 'simon-arc-solve-fractal-v3'
api = HfApi()
username = api.whoami()['name']
repo_url = api.create_repo(repo_id=repo_id, exist_ok=True, private=True, repo_type="dataset")
```
### Steps to reproduce the bug
Go https://huggingface.co/new-dataset
Fill in the form.
Click `Create dataset`.
Now the form is cleared. And the page doesn't jump anywhere.
### Expected behavior
The moment the user clicks `Create dataset`, the repo gets created and the page jumps to the created repo.
### Environment info
Firefox 128.0.3 (64-bit)
macOS Sonoma 14.5
| {
"avatar_url": "https://avatars.githubusercontent.com/u/147971?v=4",
"events_url": "https://api.github.com/users/neoneye/events{/privacy}",
"followers_url": "https://api.github.com/users/neoneye/followers",
"following_url": "https://api.github.com/users/neoneye/following{/other_user}",
"gists_url": "https://api.github.com/users/neoneye/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/neoneye",
"id": 147971,
"login": "neoneye",
"node_id": "MDQ6VXNlcjE0Nzk3MQ==",
"organizations_url": "https://api.github.com/users/neoneye/orgs",
"received_events_url": "https://api.github.com/users/neoneye/received_events",
"repos_url": "https://api.github.com/users/neoneye/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/neoneye/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neoneye/subscriptions",
"type": "User",
"url": "https://api.github.com/users/neoneye"
} | https://api.github.com/repos/huggingface/datasets/issues/7108/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7108/timeline | closed | false | 7,108 | null | 2024-08-19T06:52:48Z | null | false |
2,470,444,732 | https://api.github.com/repos/huggingface/datasets/issues/7107 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7107/events | [] | null | 2024-08-18T09:28:43Z | [] | https://github.com/huggingface/datasets/issues/7107 | NONE | completed | null | null | [
"There seems to be a PR related to the load_dataset path that went into 2.21.0 -- https://github.com/huggingface/datasets/pull/6862/files\r\n\r\nTaking a look at it now",
"+1\r\n\r\nDowngrading to 2.20.0 fixed my issue, hopefully helpful for others.",
"I tried adding a simple test to `test_load.py` with the alp... | load_dataset broken in 2.21.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7107/reactions"
} | I_kwDODunzps6TP_68 | null | 2024-08-16T14:59:51Z | https://api.github.com/repos/huggingface/datasets/issues/7107/comments | ### Describe the bug
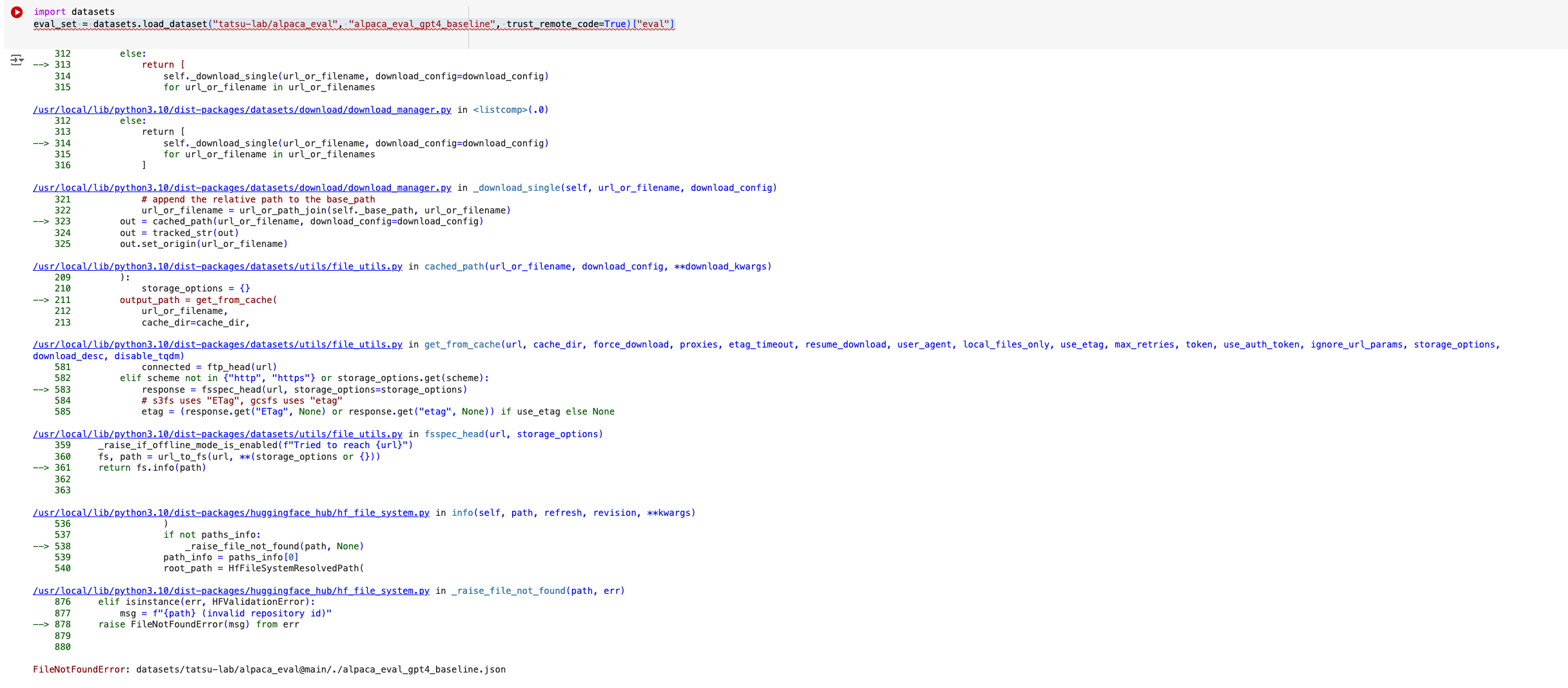
`eval_set = datasets.load_dataset("tatsu-lab/alpaca_eval", "alpaca_eval_gpt4_baseline", trust_remote_code=True)`
used to work till 2.20.0 but doesn't work in 2.21.0
In 2.20.0:

in 2.21.0:
### Steps to reproduce the bug
1. Spin up a new google collab
2. `pip install datasets==2.21.0`
3. `import datasets`
4. `eval_set = datasets.load_dataset("tatsu-lab/alpaca_eval", "alpaca_eval_gpt4_baseline", trust_remote_code=True)`
5. Will throw an error.
### Expected behavior
Try steps 1-5 again but replace datasets version with 2.20.0, it will work
### Environment info
- `datasets` version: 2.21.0
- Platform: Linux-6.1.85+-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.23.5
- PyArrow version: 17.0.0
- Pandas version: 2.1.4
- `fsspec` version: 2024.5.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/1911631?v=4",
"events_url": "https://api.github.com/users/anjor/events{/privacy}",
"followers_url": "https://api.github.com/users/anjor/followers",
"following_url": "https://api.github.com/users/anjor/following{/other_user}",
"gists_url": "https://api.github.com/users/anjor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/anjor",
"id": 1911631,
"login": "anjor",
"node_id": "MDQ6VXNlcjE5MTE2MzE=",
"organizations_url": "https://api.github.com/users/anjor/orgs",
"received_events_url": "https://api.github.com/users/anjor/received_events",
"repos_url": "https://api.github.com/users/anjor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/anjor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anjor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/anjor"
} | https://api.github.com/repos/huggingface/datasets/issues/7107/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7107/timeline | closed | false | 7,107 | null | 2024-08-18T09:27:12Z | null | false |
2,469,854,262 | https://api.github.com/repos/huggingface/datasets/issues/7106 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7106/events | [] | null | 2024-08-16T09:31:37Z | [] | https://github.com/huggingface/datasets/pull/7106 | MEMBER | null | false | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7106). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | Rename LargeList.dtype to LargeList.feature | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7106/reactions"
} | PR_kwDODunzps54jntM | {
"diff_url": "https://github.com/huggingface/datasets/pull/7106.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7106",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7106.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7106"
} | 2024-08-16T09:12:04Z | https://api.github.com/repos/huggingface/datasets/issues/7106/comments | Rename `LargeList.dtype` to `LargeList.feature`.
Note that `dtype` is usually used for NumPy data types ("int64", "float32",...): see `Value.dtype`.
However, `LargeList` attribute (like `Sequence.feature`) expects a `FeatureType` instead.
With this renaming:
- we avoid confusion about the expected type and
- we also align `LargeList` with `Sequence`. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | https://api.github.com/repos/huggingface/datasets/issues/7106/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7106/timeline | open | false | 7,106 | null | null | null | true |
2,468,207,039 | https://api.github.com/repos/huggingface/datasets/issues/7105 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7105/events | [] | null | 2024-08-19T15:08:49Z | [] | https://github.com/huggingface/datasets/pull/7105 | MEMBER | null | false | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7105). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Nice\r\n\r\n<img width=\"141\" alt=\"Capture d’écran 2024-08-19 à 15 25 00\" src=\"ht... | Use `huggingface_hub` cache | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 2,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7105/reactions"
} | PR_kwDODunzps54eZ0D | {
"diff_url": "https://github.com/huggingface/datasets/pull/7105.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7105",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7105.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7105"
} | 2024-08-15T14:45:22Z | https://api.github.com/repos/huggingface/datasets/issues/7105/comments | wip
- use `hf_hub_download()` from `huggingface_hub` for HF files
- `datasets` cache_dir is still used for:
- caching datasets as Arrow files (that back `Dataset` objects)
- extracted archives, uncompressed files
- files downloaded via http (datasets with scripts)
- I removed code that were made for http files (and also the dummy_data / mock_download_manager stuff that happened to rely on them and have been legacy for a while now) | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | https://api.github.com/repos/huggingface/datasets/issues/7105/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7105/timeline | open | false | 7,105 | null | null | null | true |
2,467,788,212 | https://api.github.com/repos/huggingface/datasets/issues/7104 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7104/events | [] | null | 2024-08-15T10:24:13Z | [] | https://github.com/huggingface/datasets/pull/7104 | MEMBER | null | false | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7104). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | remove more script docs | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7104/reactions"
} | PR_kwDODunzps54dAhE | {
"diff_url": "https://github.com/huggingface/datasets/pull/7104.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7104",
"merged_at": "2024-08-15T10:18:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7104.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7104"
} | 2024-08-15T10:13:26Z | https://api.github.com/repos/huggingface/datasets/issues/7104/comments | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | https://api.github.com/repos/huggingface/datasets/issues/7104/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7104/timeline | closed | false | 7,104 | null | 2024-08-15T10:18:25Z | null | true |
2,467,664,581 | https://api.github.com/repos/huggingface/datasets/issues/7103 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7103/events | [] | null | 2024-08-16T09:18:29Z | [] | https://github.com/huggingface/datasets/pull/7103 | MEMBER | null | false | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7103). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | Fix args of feature docstrings | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7103/reactions"
} | PR_kwDODunzps54clrp | {
"diff_url": "https://github.com/huggingface/datasets/pull/7103.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7103",
"merged_at": "2024-08-15T10:33:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7103.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7103"
} | 2024-08-15T08:46:08Z | https://api.github.com/repos/huggingface/datasets/issues/7103/comments | Fix Args section of feature docstrings.
Currently, some args do not appear in the docs because they are not properly parsed due to the lack of their type (between parentheses). | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | https://api.github.com/repos/huggingface/datasets/issues/7103/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7103/timeline | closed | false | 7,103 | null | 2024-08-15T10:33:30Z | null | true |
2,466,893,106 | https://api.github.com/repos/huggingface/datasets/issues/7102 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7102/events | [] | null | 2024-08-15T16:17:31Z | [] | https://github.com/huggingface/datasets/issues/7102 | NONE | null | null | null | [
"Hi @lajd , I was skeptical about how we are saving the shards each as their own dataset (arrow file) in the script above, and so I updated the script to try out saving the shards in a few different file formats. From the experiments I ran, I saw binary format show significantly the best performance, with arrow a... | Slow iteration speeds when using IterableDataset.shuffle with load_dataset(data_files=..., streaming=True) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7102/reactions"
} | I_kwDODunzps6TCc0y | null | 2024-08-14T21:44:44Z | https://api.github.com/repos/huggingface/datasets/issues/7102/comments | ### Describe the bug
When I load a dataset from a number of arrow files, as in:
```
random_dataset = load_dataset(
"arrow",
data_files={split: shard_filepaths},
streaming=True,
split=split,
)
```
I'm able to get fast iteration speeds when iterating over the dataset without shuffling.
When I shuffle the dataset, the iteration speed is reduced by ~1000x.
It's very possible the way I'm loading dataset shards is not appropriate; if so please advise!
Thanks for the help
### Steps to reproduce the bug
Here's full code to reproduce the issue:
- Generate a random dataset
- Create shards of data independently using Dataset.save_to_disk()
- The below will generate 16 shards (arrow files), of 512 examples each
```
import time
from pathlib import Path
from multiprocessing import Pool, cpu_count
import torch
from datasets import Dataset, load_dataset
split = "train"
split_save_dir = "/tmp/random_split"
def generate_random_example():
return {
'inputs': torch.randn(128).tolist(),
'indices': torch.randint(0, 10000, (2, 20000)).tolist(),
'values': torch.randn(20000).tolist(),
}
def generate_shard_dataset(examples_per_shard: int = 512):
dataset_dict = {
'inputs': [],
'indices': [],
'values': []
}
for _ in range(examples_per_shard):
example = generate_random_example()
dataset_dict['inputs'].append(example['inputs'])
dataset_dict['indices'].append(example['indices'])
dataset_dict['values'].append(example['values'])
return Dataset.from_dict(dataset_dict)
def save_shard(shard_idx, save_dir, examples_per_shard):
shard_dataset = generate_shard_dataset(examples_per_shard)
shard_write_path = Path(save_dir) / f"shard_{shard_idx}"
shard_dataset.save_to_disk(shard_write_path)
return str(Path(shard_write_path) / "data-00000-of-00001.arrow")
def generate_split_shards(save_dir, num_shards: int = 16, examples_per_shard: int = 512):
with Pool(cpu_count()) as pool:
args = [(m, save_dir, examples_per_shard) for m in range(num_shards)]
shard_filepaths = pool.starmap(save_shard, args)
return shard_filepaths
shard_filepaths = generate_split_shards(split_save_dir)
```
Load the dataset as IterableDataset:
```
random_dataset = load_dataset(
"arrow",
data_files={split: shard_filepaths},
streaming=True,
split=split,
)
random_dataset = random_dataset.with_format("numpy")
```
Observe the iterations/second when iterating over the dataset directly, and applying shuffling before iterating:
Without shuffling, this gives ~1500 iterations/second
```
start_time = time.time()
for count, item in enumerate(random_dataset):
if count > 0 and count % 100 == 0:
elapsed_time = time.time() - start_time
iterations_per_second = count / elapsed_time
print(f"Processed {count} items at an average of {iterations_per_second:.2f} iterations/second")
```
```
Processed 100 items at an average of 705.74 iterations/second
Processed 200 items at an average of 1169.68 iterations/second
Processed 300 items at an average of 1497.97 iterations/second
Processed 400 items at an average of 1739.62 iterations/second
Processed 500 items at an average of 1931.11 iterations/second`
```
When shuffling, this gives ~3 iterations/second:
```
random_dataset = random_dataset.shuffle(buffer_size=100,seed=42)
start_time = time.time()
for count, item in enumerate(random_dataset):
if count > 0 and count % 100 == 0:
elapsed_time = time.time() - start_time
iterations_per_second = count / elapsed_time
print(f"Processed {count} items at an average of {iterations_per_second:.2f} iterations/second")
```
```
Processed 100 items at an average of 3.75 iterations/second
Processed 200 items at an average of 3.93 iterations/second
```
### Expected behavior
Iterations per second should be barely affected by shuffling, especially with a small buffer size
### Environment info
Datasets version: 2.21.0
Python 3.10
Ubuntu 22.04 | {
"avatar_url": "https://avatars.githubusercontent.com/u/13192126?v=4",
"events_url": "https://api.github.com/users/lajd/events{/privacy}",
"followers_url": "https://api.github.com/users/lajd/followers",
"following_url": "https://api.github.com/users/lajd/following{/other_user}",
"gists_url": "https://api.github.com/users/lajd/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lajd",
"id": 13192126,
"login": "lajd",
"node_id": "MDQ6VXNlcjEzMTkyMTI2",
"organizations_url": "https://api.github.com/users/lajd/orgs",
"received_events_url": "https://api.github.com/users/lajd/received_events",
"repos_url": "https://api.github.com/users/lajd/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lajd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lajd/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lajd"
} | https://api.github.com/repos/huggingface/datasets/issues/7102/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7102/timeline | open | false | 7,102 | null | null | null | false |
2,466,510,783 | https://api.github.com/repos/huggingface/datasets/issues/7101 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7101/events | [] | null | 2024-08-18T10:33:38Z | [] | https://github.com/huggingface/datasets/issues/7101 | NONE | null | null | null | [
"Having looked into this further it seems the core of the issue is with two different formats in the same repo.\r\n\r\nWhen the `parquet` config is first, the `WebDataset`s are loaded as `parquet`, if the `WebDataset` configs are first, the `parquet` is loaded as `WebDataset`.\r\n\r\nA workaround in my case would b... | `load_dataset` from Hub with `name` to specify `config` using incorrect builder type when multiple data formats are present | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7101/reactions"
} | I_kwDODunzps6TA_e_ | null | 2024-08-14T18:12:25Z | https://api.github.com/repos/huggingface/datasets/issues/7101/comments | Following [documentation](https://huggingface.co/docs/datasets/repository_structure#define-your-splits-and-subsets-in-yaml) I had defined different configs for [`Dataception`](https://huggingface.co/datasets/bigdata-pw/Dataception), a dataset of datasets:
```yaml
configs:
- config_name: dataception
data_files:
- path: dataception.parquet
split: train
default: true
- config_name: dataset_5423
data_files:
- path: datasets/5423.tar
split: train
...
- config_name: dataset_721736
data_files:
- path: datasets/721736.tar
split: train
```
The intent was for metadata to be browsable via Dataset Viewer, in addition to each individual dataset, and to allow datasets to be loaded by specifying the config/name to `load_dataset`.
While testing `load_dataset` I encountered the following error:
```python
>>> dataset = load_dataset("bigdata-pw/Dataception", "dataset_7691")
Downloading readme: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 467k/467k [00:00<00:00, 1.99MB/s]
Downloading data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 71.0M/71.0M [00:02<00:00, 26.8MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "datasets\load.py", line 2145, in load_dataset
builder_instance.download_and_prepare(
File "datasets\builder.py", line 1027, in download_and_prepare
self._download_and_prepare(
File "datasets\builder.py", line 1100, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "datasets\packaged_modules\parquet\parquet.py", line 58, in _split_generators
self.info.features = datasets.Features.from_arrow_schema(pq.read_schema(f))
^^^^^^^^^^^^^^^^^
File "pyarrow\parquet\core.py", line 2325, in read_schema
file = ParquetFile(
^^^^^^^^^^^^
File "pyarrow\parquet\core.py", line 318, in __init__
self.reader.open(
File "pyarrow\_parquet.pyx", line 1470, in pyarrow._parquet.ParquetReader.open
File "pyarrow\error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.
```
The correct file is downloaded, however the incorrect builder type is detected; `parquet` due to other content of the repository. It would appear that the config needs to be taken into account.
Note that I have removed the additional configs from the repository because of this issue and there is a limit of 3000 configs anyway so the Dataset Viewer doesn't work as I intended. I'll add them back in if it assists with testing.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/106811348?v=4",
"events_url": "https://api.github.com/users/hlky/events{/privacy}",
"followers_url": "https://api.github.com/users/hlky/followers",
"following_url": "https://api.github.com/users/hlky/following{/other_user}",
"gists_url": "https://api.github.com/users/hlky/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hlky",
"id": 106811348,
"login": "hlky",
"node_id": "U_kgDOBl3P1A",
"organizations_url": "https://api.github.com/users/hlky/orgs",
"received_events_url": "https://api.github.com/users/hlky/received_events",
"repos_url": "https://api.github.com/users/hlky/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hlky/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hlky/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hlky"
} | https://api.github.com/repos/huggingface/datasets/issues/7101/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7101/timeline | open | false | 7,101 | null | null | null | false |
2,465,529,414 | https://api.github.com/repos/huggingface/datasets/issues/7100 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7100/events | [] | null | 2024-08-14T11:01:51Z | [] | https://github.com/huggingface/datasets/issues/7100 | NONE | null | null | null | [] | IterableDataset: cannot resolve features from list of numpy arrays | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7100/reactions"
} | I_kwDODunzps6S9P5G | null | 2024-08-14T11:01:51Z | https://api.github.com/repos/huggingface/datasets/issues/7100/comments | ### Describe the bug
when resolve features of `IterableDataset`, got `pyarrow.lib.ArrowInvalid: Can only convert 1-dimensional array values` error.
```
Traceback (most recent call last):
File "test.py", line 6
iter_ds = iter_ds._resolve_features()
File "lib/python3.10/site-packages/datasets/iterable_dataset.py", line 2876, in _resolve_features
features = _infer_features_from_batch(self.with_format(None)._head())
File "lib/python3.10/site-packages/datasets/iterable_dataset.py", line 63, in _infer_features_from_batch
pa_table = pa.Table.from_pydict(batch)
File "pyarrow/table.pxi", line 1813, in pyarrow.lib._Tabular.from_pydict
File "pyarrow/table.pxi", line 5339, in pyarrow.lib._from_pydict
File "pyarrow/array.pxi", line 374, in pyarrow.lib.asarray
File "pyarrow/array.pxi", line 344, in pyarrow.lib.array
File "pyarrow/array.pxi", line 42, in pyarrow.lib._sequence_to_array
File "pyarrow/error.pxi", line 154, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Can only convert 1-dimensional array values
```
### Steps to reproduce the bug
```python
from datasets import Dataset
import numpy as np
# create list of numpy
iter_ds = Dataset.from_dict({'a': [[[1, 2, 3], [1, 2, 3]]]}).to_iterable_dataset().map(lambda x: {'a': [np.array(x['a'])]})
iter_ds = iter_ds._resolve_features() # errors here
```
### Expected behavior
features can be successfully resolved
### Environment info
- `datasets` version: 2.21.0
- Platform: Linux-5.15.0-94-generic-x86_64-with-glibc2.35
- Python version: 3.10.13
- `huggingface_hub` version: 0.23.4
- PyArrow version: 15.0.0
- Pandas version: 2.2.0
- `fsspec` version: 2023.10.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/18899212?v=4",
"events_url": "https://api.github.com/users/VeryLazyBoy/events{/privacy}",
"followers_url": "https://api.github.com/users/VeryLazyBoy/followers",
"following_url": "https://api.github.com/users/VeryLazyBoy/following{/other_user}",
"gists_url": "https://api.github.com/users/VeryLazyBoy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/VeryLazyBoy",
"id": 18899212,
"login": "VeryLazyBoy",
"node_id": "MDQ6VXNlcjE4ODk5MjEy",
"organizations_url": "https://api.github.com/users/VeryLazyBoy/orgs",
"received_events_url": "https://api.github.com/users/VeryLazyBoy/received_events",
"repos_url": "https://api.github.com/users/VeryLazyBoy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/VeryLazyBoy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VeryLazyBoy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/VeryLazyBoy"
} | https://api.github.com/repos/huggingface/datasets/issues/7100/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7100/timeline | open | false | 7,100 | null | null | null | false |
2,465,221,827 | https://api.github.com/repos/huggingface/datasets/issues/7099 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7099/events | [] | null | 2024-08-14T08:45:17Z | [] | https://github.com/huggingface/datasets/pull/7099 | MEMBER | null | false | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7099). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | Set dev version | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7099/reactions"
} | PR_kwDODunzps54U7s4 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7099.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7099",
"merged_at": "2024-08-14T08:39:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7099.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7099"
} | 2024-08-14T08:31:17Z | https://api.github.com/repos/huggingface/datasets/issues/7099/comments | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | https://api.github.com/repos/huggingface/datasets/issues/7099/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7099/timeline | closed | false | 7,099 | null | 2024-08-14T08:39:25Z | null | true |
2,465,016,562 | https://api.github.com/repos/huggingface/datasets/issues/7098 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7098/events | [] | null | 2024-08-14T06:41:07Z | [] | https://github.com/huggingface/datasets/pull/7098 | MEMBER | null | false | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7098). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | Release: 2.21.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7098/reactions"
} | PR_kwDODunzps54UPMS | {
"diff_url": "https://github.com/huggingface/datasets/pull/7098.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7098",
"merged_at": "2024-08-14T06:41:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7098.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7098"
} | 2024-08-14T06:35:13Z | https://api.github.com/repos/huggingface/datasets/issues/7098/comments | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | https://api.github.com/repos/huggingface/datasets/issues/7098/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7098/timeline | closed | false | 7,098 | null | 2024-08-14T06:41:06Z | null | true |
2,458,455,489 | https://api.github.com/repos/huggingface/datasets/issues/7097 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7097/events | [] | null | 2024-08-09T18:26:37Z | [] | https://github.com/huggingface/datasets/issues/7097 | NONE | null | null | null | [] | Some of DownloadConfig's properties are always being overridden in load.py | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7097/reactions"
} | I_kwDODunzps6SiQ3B | null | 2024-08-09T18:26:37Z | https://api.github.com/repos/huggingface/datasets/issues/7097/comments | ### Describe the bug
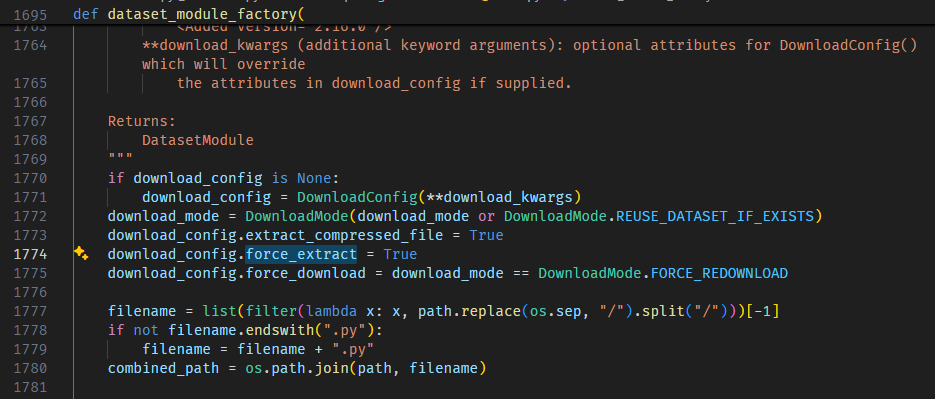
The `extract_compressed_file` and `force_extract` properties of DownloadConfig are always being set to True in the function `dataset_module_factory` in the `load.py` file. This behavior is very annoying because data extracted will just be ignored the next time the dataset is loaded.
See this image below:
### Steps to reproduce the bug
1. Have a local dataset that contains archived files (zip, tar.gz, etc)
2. Build a dataset loading script to download and extract these files
3. Run the load_dataset function with a DownloadConfig that specifically set `force_extract` to False
4. The extraction process will start no matter if the archives was extracted previously
### Expected behavior
The extraction process should not run when the archives were previously extracted and `force_extract` is set to False.
### Environment info
datasets==2.20.0
python3.9 | {
"avatar_url": "https://avatars.githubusercontent.com/u/29772899?v=4",
"events_url": "https://api.github.com/users/ductai199x/events{/privacy}",
"followers_url": "https://api.github.com/users/ductai199x/followers",
"following_url": "https://api.github.com/users/ductai199x/following{/other_user}",
"gists_url": "https://api.github.com/users/ductai199x/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ductai199x",
"id": 29772899,
"login": "ductai199x",
"node_id": "MDQ6VXNlcjI5NzcyODk5",
"organizations_url": "https://api.github.com/users/ductai199x/orgs",
"received_events_url": "https://api.github.com/users/ductai199x/received_events",
"repos_url": "https://api.github.com/users/ductai199x/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ductai199x/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ductai199x/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ductai199x"
} | https://api.github.com/repos/huggingface/datasets/issues/7097/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7097/timeline | open | false | 7,097 | null | null | null | false |
2,456,929,173 | https://api.github.com/repos/huggingface/datasets/issues/7096 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7096/events | [] | null | 2024-08-15T17:25:26Z | [] | https://github.com/huggingface/datasets/pull/7096 | CONTRIBUTOR | null | false | null | [
"Hi @albertvillanova, is this PR looking okay to you? Anything else you'd like to see?",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7096). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",... | Automatically create `cache_dir` from `cache_file_name` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7096/reactions"
} | PR_kwDODunzps535Xkr | {
"diff_url": "https://github.com/huggingface/datasets/pull/7096.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7096",
"merged_at": "2024-08-15T10:13:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7096.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7096"
} | 2024-08-09T01:34:06Z | https://api.github.com/repos/huggingface/datasets/issues/7096/comments | You get a pretty unhelpful error message when specifying a `cache_file_name` in a directory that doesn't exist, e.g. `cache_file_name="./cache/data.map"`
```python
import datasets
cache_file_name="./cache/train.map"
dataset = datasets.load_dataset("ylecun/mnist")
dataset["train"].map(lambda x: x, cache_file_name=cache_file_name)
```
```
FileNotFoundError: [Errno 2] No such file or directory: '/.../cache/tmp48r61siw'
```
It is simple enough to create and I was expecting that this would have been the case.
cc: @albertvillanova @lhoestq | {
"avatar_url": "https://avatars.githubusercontent.com/u/27844407?v=4",
"events_url": "https://api.github.com/users/ringohoffman/events{/privacy}",
"followers_url": "https://api.github.com/users/ringohoffman/followers",
"following_url": "https://api.github.com/users/ringohoffman/following{/other_user}",
"gists_url": "https://api.github.com/users/ringohoffman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ringohoffman",
"id": 27844407,
"login": "ringohoffman",
"node_id": "MDQ6VXNlcjI3ODQ0NDA3",
"organizations_url": "https://api.github.com/users/ringohoffman/orgs",
"received_events_url": "https://api.github.com/users/ringohoffman/received_events",
"repos_url": "https://api.github.com/users/ringohoffman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ringohoffman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ringohoffman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ringohoffman"
} | https://api.github.com/repos/huggingface/datasets/issues/7096/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7096/timeline | closed | false | 7,096 | null | 2024-08-15T10:13:22Z | null | true |
2,454,418,130 | https://api.github.com/repos/huggingface/datasets/issues/7094 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7094/events | [] | null | 2024-08-07T21:53:06Z | [] | https://github.com/huggingface/datasets/pull/7094 | NONE | null | false | null | [] | Add Arabic Docs to Datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7094/reactions"
} | PR_kwDODunzps53w2b7 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7094.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7094",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7094.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7094"
} | 2024-08-07T21:53:06Z | https://api.github.com/repos/huggingface/datasets/issues/7094/comments | Translate Docs into Arabic issue-number : #7093
[Arabic Docs](https://github.com/AhmedAlmaghz/datasets/blob/main/docs/source/ar/index.mdx)
[English Docs](https://github.com/AhmedAlmaghz/datasets/blob/main/docs/source/en/index.mdx)
@stevhliu | {
"avatar_url": "https://avatars.githubusercontent.com/u/53489256?v=4",
"events_url": "https://api.github.com/users/AhmedAlmaghz/events{/privacy}",
"followers_url": "https://api.github.com/users/AhmedAlmaghz/followers",
"following_url": "https://api.github.com/users/AhmedAlmaghz/following{/other_user}",
"gists_url": "https://api.github.com/users/AhmedAlmaghz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AhmedAlmaghz",
"id": 53489256,
"login": "AhmedAlmaghz",
"node_id": "MDQ6VXNlcjUzNDg5MjU2",
"organizations_url": "https://api.github.com/users/AhmedAlmaghz/orgs",
"received_events_url": "https://api.github.com/users/AhmedAlmaghz/received_events",
"repos_url": "https://api.github.com/users/AhmedAlmaghz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AhmedAlmaghz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AhmedAlmaghz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AhmedAlmaghz"
} | https://api.github.com/repos/huggingface/datasets/issues/7094/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7094/timeline | open | false | 7,094 | null | null | null | true |
2,454,413,074 | https://api.github.com/repos/huggingface/datasets/issues/7093 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7093/events | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null | 2024-08-07T21:48:05Z | [] | https://github.com/huggingface/datasets/issues/7093 | NONE | null | null | null | [] | Add Arabic Docs to datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7093/reactions"
} | I_kwDODunzps6SS18S | null | 2024-08-07T21:48:05Z | https://api.github.com/repos/huggingface/datasets/issues/7093/comments | ### Feature request
Add Arabic Docs to datasets
[Datasets Arabic](https://github.com/AhmedAlmaghz/datasets/blob/main/docs/source/ar/index.mdx)
### Motivation
@AhmedAlmaghz
https://github.com/AhmedAlmaghz/datasets/blob/main/docs/source/ar/index.mdx
### Your contribution
@AhmedAlmaghz
https://github.com/AhmedAlmaghz/datasets/blob/main/docs/source/ar/index.mdx | {
"avatar_url": "https://avatars.githubusercontent.com/u/53489256?v=4",
"events_url": "https://api.github.com/users/AhmedAlmaghz/events{/privacy}",
"followers_url": "https://api.github.com/users/AhmedAlmaghz/followers",
"following_url": "https://api.github.com/users/AhmedAlmaghz/following{/other_user}",
"gists_url": "https://api.github.com/users/AhmedAlmaghz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AhmedAlmaghz",
"id": 53489256,
"login": "AhmedAlmaghz",
"node_id": "MDQ6VXNlcjUzNDg5MjU2",
"organizations_url": "https://api.github.com/users/AhmedAlmaghz/orgs",
"received_events_url": "https://api.github.com/users/AhmedAlmaghz/received_events",
"repos_url": "https://api.github.com/users/AhmedAlmaghz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AhmedAlmaghz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AhmedAlmaghz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AhmedAlmaghz"
} | https://api.github.com/repos/huggingface/datasets/issues/7093/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7093/timeline | open | false | 7,093 | null | null | null | false |
2,451,393,658 | https://api.github.com/repos/huggingface/datasets/issues/7092 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7092/events | [] | null | 2024-08-08T16:35:01Z | [] | https://github.com/huggingface/datasets/issues/7092 | NONE | null | null | null | [
"I’ll take a look",
"Possible definitions of done for this issue:\r\n\r\n1. A fix so you can load your dataset specifically\r\n2. A general fix for datasets similar to this in the `datasets` library\r\n\r\nOption 1 is trivial. I think option 2 requires significant changes to the library.\r\n\r\nSince you outlined... | load_dataset with multiple jsonlines files interprets datastructure too early | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7092/reactions"
} | I_kwDODunzps6SHUx6 | null | 2024-08-06T17:42:55Z | https://api.github.com/repos/huggingface/datasets/issues/7092/comments | ### Describe the bug
likely related to #6460
using `datasets.load_dataset("json", data_dir= ... )` with multiple `.jsonl` files will error if one of the files (maybe the first file?) contains a full column of empty data.
### Steps to reproduce the bug
real world example:
data is available in this [PR-branch](https://github.com/Vipitis/shadertoys-dataset/pull/3/commits/cb1e7157814f74acb09d5dc2f1be3c0a868a9933). Because my files are chunked by months, some months contain all empty data for some columns, just by chance - these are `[]`. Otherwise it's all the same structure.
```python
from datasets import load_dataset
ds = load_dataset("json", data_dir="./data/annotated/api")
```
you get a long error trace, where in the middle it says something like
```cs
TypeError: Couldn't cast array of type struct<id: int64, src: string, ctype: string, channel: int64, sampler: struct<filter: string, wrap: string, vflip: string, srgb: string, internal: string>, published: int64> to null
```
toy example: (on request)
### Expected behavior
Some suggestions
1. give a better error message to the user
2. consider all files before deciding on a data structure for a given column.
3. if you encounter a new structure, and can't cast that to null, replace the null-hypothesis. (maybe something for pyarrow)
as a workaround I have lazily implemented the following (essentially step 2)
```python
import os
import jsonlines
import datasets
api_files = os.listdir("./data/annotated/api")
api_files = [f"./data/annotated/api/{f}" for f in api_files]
api_file_contents = []
for f in api_files:
with jsonlines.open(f) as reader:
for obj in reader:
api_file_contents.append(obj)
ds = datasets.Dataset.from_list(api_file_contents)
```
this works fine for my usecase, but is potentially slower and less memory efficient for really large datasets (where this is unlikely to happen in the first place).
### Environment info
- `datasets` version: 2.20.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.9.4
- `huggingface_hub` version: 0.23.4
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2023.10.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/23384483?v=4",
"events_url": "https://api.github.com/users/Vipitis/events{/privacy}",
"followers_url": "https://api.github.com/users/Vipitis/followers",
"following_url": "https://api.github.com/users/Vipitis/following{/other_user}",
"gists_url": "https://api.github.com/users/Vipitis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Vipitis",
"id": 23384483,
"login": "Vipitis",
"node_id": "MDQ6VXNlcjIzMzg0NDgz",
"organizations_url": "https://api.github.com/users/Vipitis/orgs",
"received_events_url": "https://api.github.com/users/Vipitis/received_events",
"repos_url": "https://api.github.com/users/Vipitis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Vipitis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vipitis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Vipitis"
} | https://api.github.com/repos/huggingface/datasets/issues/7092/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7092/timeline | open | false | 7,092 | null | null | null | false |
2,449,699,490 | https://api.github.com/repos/huggingface/datasets/issues/7090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7090/events | [] | null | 2024-08-06T00:35:05Z | [] | https://github.com/huggingface/datasets/issues/7090 | NONE | null | null | null | [] | The test test_move_script_doesnt_change_hash fails because it runs the 'python' command while the python executable has a different name | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7090/reactions"
} | I_kwDODunzps6SA3Ki | null | 2024-08-06T00:35:05Z | https://api.github.com/repos/huggingface/datasets/issues/7090/comments | ### Describe the bug
Tests should use the same pythin path as they are launched with, which in the case of FreeBSD is /usr/local/bin/python3.11
Failure:
```
if err_filename is not None:
> raise child_exception_type(errno_num, err_msg, err_filename)
E FileNotFoundError: [Errno 2] No such file or directory: 'python'
```
### Steps to reproduce the bug
regular test run using PyTest
### Expected behavior
n/a
### Environment info
FreeBSD 14.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/271906?v=4",
"events_url": "https://api.github.com/users/yurivict/events{/privacy}",
"followers_url": "https://api.github.com/users/yurivict/followers",
"following_url": "https://api.github.com/users/yurivict/following{/other_user}",
"gists_url": "https://api.github.com/users/yurivict/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yurivict",
"id": 271906,
"login": "yurivict",
"node_id": "MDQ6VXNlcjI3MTkwNg==",
"organizations_url": "https://api.github.com/users/yurivict/orgs",
"received_events_url": "https://api.github.com/users/yurivict/received_events",
"repos_url": "https://api.github.com/users/yurivict/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yurivict/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yurivict/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yurivict"
} | https://api.github.com/repos/huggingface/datasets/issues/7090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7090/timeline | open | false | 7,090 | null | null | null | false |
2,449,479,500 | https://api.github.com/repos/huggingface/datasets/issues/7089 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7089/events | [] | null | 2024-08-05T21:05:11Z | [] | https://github.com/huggingface/datasets/issues/7089 | NONE | null | null | null | [] | Missing pyspark dependency causes the testsuite to error out, instead of a few tests to be skipped | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7089/reactions"
} | I_kwDODunzps6SABdM | null | 2024-08-05T21:05:11Z | https://api.github.com/repos/huggingface/datasets/issues/7089/comments | ### Describe the bug
see the subject
### Steps to reproduce the bug
regular tests
### Expected behavior
n/a
### Environment info
version 2.20.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/271906?v=4",
"events_url": "https://api.github.com/users/yurivict/events{/privacy}",
"followers_url": "https://api.github.com/users/yurivict/followers",
"following_url": "https://api.github.com/users/yurivict/following{/other_user}",
"gists_url": "https://api.github.com/users/yurivict/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yurivict",
"id": 271906,
"login": "yurivict",
"node_id": "MDQ6VXNlcjI3MTkwNg==",
"organizations_url": "https://api.github.com/users/yurivict/orgs",
"received_events_url": "https://api.github.com/users/yurivict/received_events",
"repos_url": "https://api.github.com/users/yurivict/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yurivict/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yurivict/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yurivict"
} | https://api.github.com/repos/huggingface/datasets/issues/7089/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7089/timeline | open | false | 7,089 | null | null | null | false |
2,447,383,940 | https://api.github.com/repos/huggingface/datasets/issues/7088 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7088/events | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null | 2024-08-05T00:45:50Z | [] | https://github.com/huggingface/datasets/issues/7088 | NONE | null | null | null | [] | Disable warning when using with_format format on tensors | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7088/reactions"
} | I_kwDODunzps6R4B2E | null | 2024-08-05T00:45:50Z | https://api.github.com/repos/huggingface/datasets/issues/7088/comments | ### Feature request
If we write this code:
```python
"""Get data and define datasets."""
from enum import StrEnum
from datasets import load_dataset
from torch.utils.data import DataLoader
from torchvision import transforms
class Split(StrEnum):
"""Describes what type of split to use in the dataloader"""
TRAIN = "train"
TEST = "test"
VAL = "validation"
class ImageNetDataLoader(DataLoader):
"""Create an ImageNetDataloader"""
_preprocess_transform = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
]
)
def __init__(self, batch_size: int = 4, split: Split = Split.TRAIN):
dataset = (
load_dataset(
"imagenet-1k",
split=split,
trust_remote_code=True,
streaming=True,
)
.with_format("torch")
.map(self._preprocess)
)
super().__init__(dataset=dataset, batch_size=batch_size)
def _preprocess(self, data):
if data["image"].shape[0] < 3:
data["image"] = data["image"].repeat(3, 1, 1)
data["image"] = self._preprocess_transform(data["image"].float())
return data
if __name__ == "__main__":
dataloader = ImageNetDataLoader(batch_size=2)
for batch in dataloader:
print(batch["image"])
break
```
This will trigger an user warning :
```bash
datasets\formatting\torch_formatter.py:85: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
return torch.tensor(value, **{**default_dtype, **self.torch_tensor_kwargs})
```
### Motivation
This happens because the the way the formatted tensor is returned in `TorchFormatter._tensorize`.
This function handle values of different types, according to some tests it seems that possible value types are `int`, `numpy.ndarray` and `torch.Tensor`.
In particular this warning is triggered when the value type is `torch.Tensor`, because is not the suggested Pytorch way of doing it:
- https://stackoverflow.com/questions/55266154/pytorch-preferred-way-to-copy-a-tensor
- https://discuss.pytorch.org/t/it-is-recommended-to-use-source-tensor-clone-detach-or-sourcetensor-clone-detach-requires-grad-true/101218#:~:text=The%20warning%20points%20to%20wrapping%20a%20tensor%20in%20torch.tensor%2C%20which%20is%20not%20recommended.%0AInstead%20of%20torch.tensor(outputs)%20use%20outputs.clone().detach()%20or%20the%20same%20with%20.requires_grad_(True)%2C%20if%20necessary.
### Your contribution
A solution that I found to be working is to change the current way of doing it:
```python
return torch.tensor(value, **{**default_dtype, **self.torch_tensor_kwargs})
```
To:
```python
if (isinstance(value, torch.Tensor)):
tensor = value.clone().detach()
if self.torch_tensor_kwargs.get('requires_grad', False):
tensor.requires_grad_()
return tensor
else:
return torch.tensor(value, **{**default_dtype, **self.torch_tensor_kwargs})
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42048782?v=4",
"events_url": "https://api.github.com/users/Haislich/events{/privacy}",
"followers_url": "https://api.github.com/users/Haislich/followers",
"following_url": "https://api.github.com/users/Haislich/following{/other_user}",
"gists_url": "https://api.github.com/users/Haislich/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Haislich",
"id": 42048782,
"login": "Haislich",
"node_id": "MDQ6VXNlcjQyMDQ4Nzgy",
"organizations_url": "https://api.github.com/users/Haislich/orgs",
"received_events_url": "https://api.github.com/users/Haislich/received_events",
"repos_url": "https://api.github.com/users/Haislich/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Haislich/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Haislich/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Haislich"
} | https://api.github.com/repos/huggingface/datasets/issues/7088/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7088/timeline | open | false | 7,088 | null | null | null | false |
2,447,158,643 | https://api.github.com/repos/huggingface/datasets/issues/7087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7087/events | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null | 2024-08-06T06:59:23Z | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | https://github.com/huggingface/datasets/issues/7087 | NONE | completed | null | null | [
"Thanks for reporting.\r\n\r\nIt is weird, because the language entry is in the list. See: https://github.com/huggingface/huggingface.js/blob/98e32f0ed4ee057a596f66a1dec738e5db9643d5/packages/languages/src/languages_iso_639_3.ts#L15186-L15189\r\n\r\nI have reported the issue:\r\n- https://github.com/huggingface/hug... | Unable to create dataset card for Lushootseed language | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7087/reactions"
} | I_kwDODunzps6R3K1z | null | 2024-08-04T14:27:04Z | https://api.github.com/repos/huggingface/datasets/issues/7087/comments | ### Feature request
While I was creating the dataset which contained all documents from the Lushootseed Wikipedia, the dataset card asked me to enter which language the dataset was in. Since Lushootseed is a critically endangered language, it was not available as one of the options. Is it possible to allow entering languages that aren't available in the options?
### Motivation
I'd like to add more information about my dataset in the dataset card, and the language is one of the most important pieces of information, since the entire dataset is primarily concerned collecting Lushootseed documents.
### Your contribution
I can submit a pull request | {
"avatar_url": "https://avatars.githubusercontent.com/u/134876525?v=4",
"events_url": "https://api.github.com/users/vaishnavsudarshan/events{/privacy}",
"followers_url": "https://api.github.com/users/vaishnavsudarshan/followers",
"following_url": "https://api.github.com/users/vaishnavsudarshan/following{/other_user}",
"gists_url": "https://api.github.com/users/vaishnavsudarshan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vaishnavsudarshan",
"id": 134876525,
"login": "vaishnavsudarshan",
"node_id": "U_kgDOCAoNbQ",
"organizations_url": "https://api.github.com/users/vaishnavsudarshan/orgs",
"received_events_url": "https://api.github.com/users/vaishnavsudarshan/received_events",
"repos_url": "https://api.github.com/users/vaishnavsudarshan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vaishnavsudarshan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vaishnavsudarshan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vaishnavsudarshan"
} | https://api.github.com/repos/huggingface/datasets/issues/7087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7087/timeline | closed | false | 7,087 | null | 2024-08-06T06:59:22Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | false |
2,445,516,829 | https://api.github.com/repos/huggingface/datasets/issues/7086 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7086/events | [] | null | 2024-08-02T18:12:23Z | [] | https://github.com/huggingface/datasets/issues/7086 | NONE | null | null | null | [] | load_dataset ignores cached datasets and tries to hit HF Hub, resulting in API rate limit errors | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7086/reactions"
} | I_kwDODunzps6Rw6Ad | null | 2024-08-02T18:12:23Z | https://api.github.com/repos/huggingface/datasets/issues/7086/comments | ### Describe the bug
I have been running lm-eval-harness a lot which has results in an API rate limit. This seems strange, since all of the data should be cached locally. I have in fact verified this.
### Steps to reproduce the bug
1. Be Me
2. Run `load_dataset("TAUR-Lab/MuSR")`
3. Hit rate limit error
4. Dataset is in .cache/huggingface/datasets
5. ???
### Expected behavior
We should not run into API rate limits if we have cached the dataset
### Environment info
datasets 2.16.0
python 3.10.4 | {
"avatar_url": "https://avatars.githubusercontent.com/u/11379648?v=4",
"events_url": "https://api.github.com/users/tginart/events{/privacy}",
"followers_url": "https://api.github.com/users/tginart/followers",
"following_url": "https://api.github.com/users/tginart/following{/other_user}",
"gists_url": "https://api.github.com/users/tginart/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tginart",
"id": 11379648,
"login": "tginart",
"node_id": "MDQ6VXNlcjExMzc5NjQ4",
"organizations_url": "https://api.github.com/users/tginart/orgs",
"received_events_url": "https://api.github.com/users/tginart/received_events",
"repos_url": "https://api.github.com/users/tginart/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tginart/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tginart/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tginart"
} | https://api.github.com/repos/huggingface/datasets/issues/7086/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7086/timeline | open | false | 7,086 | null | null | null | false |
2,440,008,618 | https://api.github.com/repos/huggingface/datasets/issues/7085 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7085/events | [] | null | 2024-08-14T16:04:24Z | [] | https://github.com/huggingface/datasets/issues/7085 | NONE | null | null | null | [
"@lhoestq I detected this regression over on [DataDreamer](https://github.com/datadreamer-dev/DataDreamer)'s test suite. I put in these [monkey patches](https://github.com/datadreamer-dev/DataDreamer/blob/4cbaf9f39cf7bedde72bbaa68346e169788fbecb/src/_patches/datasets_reset_state_hack.py) in case that fixed it our t... | [Regression] IterableDataset is broken on 2.20.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7085/reactions"
} | I_kwDODunzps6Rb5Oq | null | 2024-07-31T13:01:59Z | https://api.github.com/repos/huggingface/datasets/issues/7085/comments | ### Describe the bug
In the latest version of datasets there is a major regression, after creating an `IterableDataset` from a generator and applying a few operations (`map`, `select`), you can no longer iterate through the dataset multiple times.
The issue seems to stem from the recent addition of "resumable IterableDatasets" (#6658) (@lhoestq). It seems like it's keeping state when it shouldn't.
### Steps to reproduce the bug
Minimal Reproducible Example (comparing `datasets==2.17.0` and `datasets==2.20.0`)
```
#!/bin/bash
# List of dataset versions to test
versions=("2.17.0" "2.20.0")
# Loop through each version
for version in "${versions[@]}"; do
# Install the specific version of the datasets library
pip3 install -q datasets=="$version" 2>/dev/null
# Run the Python script
python3 - <<EOF
from datasets import IterableDataset
from datasets.features.features import Features, Value
def test_gen():
yield from [{"foo": i} for i in range(10)]
features = Features([("foo", Value("int64"))])
d = IterableDataset.from_generator(test_gen, features=features)
mapped = d.map(lambda row: {"foo": row["foo"] * 2})
column = mapped.select_columns(["foo"])
print("Version $version - Iterate Once:", list(column))
print("Version $version - Iterate Twice:", list(column))
EOF
done
```
The output looks like this:
```
Version 2.17.0 - Iterate Once: [{'foo': 0}, {'foo': 2}, {'foo': 4}, {'foo': 6}, {'foo': 8}, {'foo': 10}, {'foo': 12}, {'foo': 14}, {'foo': 16}, {'foo': 18}]
Version 2.17.0 - Iterate Twice: [{'foo': 0}, {'foo': 2}, {'foo': 4}, {'foo': 6}, {'foo': 8}, {'foo': 10}, {'foo': 12}, {'foo': 14}, {'foo': 16}, {'foo': 18}]
Version 2.20.0 - Iterate Once: [{'foo': 0}, {'foo': 2}, {'foo': 4}, {'foo': 6}, {'foo': 8}, {'foo': 10}, {'foo': 12}, {'foo': 14}, {'foo': 16}, {'foo': 18}]
Version 2.20.0 - Iterate Twice: []
```
### Expected behavior
The expected behavior is it version 2.20.0 should behave the same as 2.17.0.
### Environment info
`datasets==2.20.0` on any platform. | {
"avatar_url": "https://avatars.githubusercontent.com/u/5404177?v=4",
"events_url": "https://api.github.com/users/AjayP13/events{/privacy}",
"followers_url": "https://api.github.com/users/AjayP13/followers",
"following_url": "https://api.github.com/users/AjayP13/following{/other_user}",
"gists_url": "https://api.github.com/users/AjayP13/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AjayP13",
"id": 5404177,
"login": "AjayP13",
"node_id": "MDQ6VXNlcjU0MDQxNzc=",
"organizations_url": "https://api.github.com/users/AjayP13/orgs",
"received_events_url": "https://api.github.com/users/AjayP13/received_events",
"repos_url": "https://api.github.com/users/AjayP13/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AjayP13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AjayP13/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AjayP13"
} | https://api.github.com/repos/huggingface/datasets/issues/7085/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7085/timeline | open | false | 7,085 | null | null | null | false |
2,439,519,534 | https://api.github.com/repos/huggingface/datasets/issues/7084 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7084/events | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null | 2024-07-31T09:05:58Z | [] | https://github.com/huggingface/datasets/issues/7084 | NONE | null | null | null | [] | More easily support streaming local files | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7084/reactions"
} | I_kwDODunzps6RaB0u | null | 2024-07-31T09:03:15Z | https://api.github.com/repos/huggingface/datasets/issues/7084/comments | ### Feature request
Simplify downloading and streaming datasets locally. Specifically, perhaps add an option to `load_dataset(..., streaming="download_first")` or add better support for streaming symlinked or arrow files.
### Motivation
I have downloaded FineWeb-edu locally and currently trying to stream the dataset from the local files. I have both the raw parquet files using `hugginface-cli download --repo-type dataset HuggingFaceFW/fineweb-edu` and the processed arrow files using `load_dataset("HuggingFaceFW/fineweb-edu")`.
Streaming the files locally does not work well for both file types for two different reasons.
**Arrow files**
When running `load_dataset("arrow", data_files={"train": "~/.cache/huggingface/datasets/HuggingFaceFW___fineweb-edu/default/0.0.0/5b89d1ea9319fe101b3cbdacd89a903aca1d6052/fineweb-edu-train-*.arrow"})` resolving the data files is fast, but because `arrow` is not included in the known [extensions file list](https://github.com/huggingface/datasets/blob/ce4a0c573920607bc6c814605734091b06b860e7/src/datasets/utils/file_utils.py#L738) , all files are opened and scanned to determine the compression type. Adding `arrow` to the known extension types resolves this issue.
**Parquet files**
When running `load_dataset("arrow", data_files={"train": "~/.cache/huggingface/hub/dataset-HuggingFaceFW___fineweb-edu/snapshots/5b89d1ea9319fe101b3cbdacd89a903aca1d6052/data/CC-MAIN-*/train-*.parquet"})` the paths do not get resolved because the parquet files are symlinked from the blobs (which contain all files in case there are different versions). This occurs because the [pattern matching](https://github.com/huggingface/datasets/blob/ce4a0c573920607bc6c814605734091b06b860e7/src/datasets/data_files.py#L389) checks if the path is a file and does not check for symlinks. Symlinks (at least on my machine) are of type "other".
### Your contribution
I have created a PR for fixing arrow file streaming and symlinks. However, I have not checked locally if the tests work or new tests need to be added.
IMO, the easiest option would be to add a `streaming=download_first` option, but I'm afraid that exceeds my current knowledge of how the datasets library works. https://github.com/huggingface/datasets/pull/7083 | {
"avatar_url": "https://avatars.githubusercontent.com/u/23191892?v=4",
"events_url": "https://api.github.com/users/fschlatt/events{/privacy}",
"followers_url": "https://api.github.com/users/fschlatt/followers",
"following_url": "https://api.github.com/users/fschlatt/following{/other_user}",
"gists_url": "https://api.github.com/users/fschlatt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fschlatt",
"id": 23191892,
"login": "fschlatt",
"node_id": "MDQ6VXNlcjIzMTkxODky",
"organizations_url": "https://api.github.com/users/fschlatt/orgs",
"received_events_url": "https://api.github.com/users/fschlatt/received_events",
"repos_url": "https://api.github.com/users/fschlatt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fschlatt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fschlatt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fschlatt"
} | https://api.github.com/repos/huggingface/datasets/issues/7084/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7084/timeline | open | false | 7,084 | null | null | null | false |
2,439,518,466 | https://api.github.com/repos/huggingface/datasets/issues/7083 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7083/events | [] | null | 2024-08-15T14:08:04Z | [] | https://github.com/huggingface/datasets/pull/7083 | NONE | null | false | null | [] | fix streaming from arrow files | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7083/reactions"
} | PR_kwDODunzps5292hC | {
"diff_url": "https://github.com/huggingface/datasets/pull/7083.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7083",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7083.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7083"
} | 2024-07-31T09:02:42Z | https://api.github.com/repos/huggingface/datasets/issues/7083/comments | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/23191892?v=4",
"events_url": "https://api.github.com/users/fschlatt/events{/privacy}",
"followers_url": "https://api.github.com/users/fschlatt/followers",
"following_url": "https://api.github.com/users/fschlatt/following{/other_user}",
"gists_url": "https://api.github.com/users/fschlatt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fschlatt",
"id": 23191892,
"login": "fschlatt",
"node_id": "MDQ6VXNlcjIzMTkxODky",
"organizations_url": "https://api.github.com/users/fschlatt/orgs",
"received_events_url": "https://api.github.com/users/fschlatt/received_events",
"repos_url": "https://api.github.com/users/fschlatt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fschlatt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fschlatt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fschlatt"
} | https://api.github.com/repos/huggingface/datasets/issues/7083/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7083/timeline | open | false | 7,083 | null | null | null | true |
2,437,354,975 | https://api.github.com/repos/huggingface/datasets/issues/7082 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7082/events | [] | null | 2024-08-08T08:29:55Z | [] | https://github.com/huggingface/datasets/pull/7082 | MEMBER | null | false | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7082). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | Support HTTP authentication in non-streaming mode | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7082/reactions"
} | PR_kwDODunzps522dTJ | {
"diff_url": "https://github.com/huggingface/datasets/pull/7082.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7082",
"merged_at": "2024-08-08T08:24:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7082.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7082"
} | 2024-07-30T09:25:49Z | https://api.github.com/repos/huggingface/datasets/issues/7082/comments | Support HTTP authentication in non-streaming mode, by support passing HTTP storage_options in non-streaming mode.
- Note that currently, HTTP authentication is supported only in streaming mode.
For example, this is necessary if a remote HTTP host requires authentication to download the data. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | https://api.github.com/repos/huggingface/datasets/issues/7082/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7082/timeline | closed | false | 7,082 | null | 2024-08-08T08:24:06Z | null | true |
2,437,059,657 | https://api.github.com/repos/huggingface/datasets/issues/7081 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7081/events | [] | null | 2024-07-30T08:30:37Z | [] | https://github.com/huggingface/datasets/pull/7081 | MEMBER | null | false | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7081). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | Set load_from_disk path type as PathLike | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7081/reactions"
} | PR_kwDODunzps521cGm | {
"diff_url": "https://github.com/huggingface/datasets/pull/7081.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7081",
"merged_at": "2024-07-30T08:21:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7081.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7081"
} | 2024-07-30T07:00:38Z | https://api.github.com/repos/huggingface/datasets/issues/7081/comments | Set `load_from_disk` path type as `PathLike`. This way it is aligned with `save_to_disk`. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | https://api.github.com/repos/huggingface/datasets/issues/7081/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7081/timeline | closed | false | 7,081 | null | 2024-07-30T08:21:50Z | null | true |
2,434,275,664 | https://api.github.com/repos/huggingface/datasets/issues/7080 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7080/events | [] | null | 2024-07-29T01:42:43Z | [] | https://github.com/huggingface/datasets/issues/7080 | NONE | null | null | null | [] | Generating train split takes a long time | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7080/reactions"
} | I_kwDODunzps6RGBlQ | null | 2024-07-29T01:42:43Z | https://api.github.com/repos/huggingface/datasets/issues/7080/comments | ### Describe the bug
Loading a simple webdataset takes ~45 minutes.
### Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("PixArt-alpha/SAM-LLaVA-Captions10M")
```
### Expected behavior
The dataset should load immediately as it does when loaded through a normal indexed WebDataset loader. Generating splits should be optional and there should be a message showing how to disable it.
### Environment info
- `datasets` version: 2.20.0
- Platform: Linux-4.18.0-372.32.1.el8_6.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.14
- `huggingface_hub` version: 0.24.1
- PyArrow version: 16.1.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.5.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/35648800?v=4",
"events_url": "https://api.github.com/users/alexanderswerdlow/events{/privacy}",
"followers_url": "https://api.github.com/users/alexanderswerdlow/followers",
"following_url": "https://api.github.com/users/alexanderswerdlow/following{/other_user}",
"gists_url": "https://api.github.com/users/alexanderswerdlow/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alexanderswerdlow",
"id": 35648800,
"login": "alexanderswerdlow",
"node_id": "MDQ6VXNlcjM1NjQ4ODAw",
"organizations_url": "https://api.github.com/users/alexanderswerdlow/orgs",
"received_events_url": "https://api.github.com/users/alexanderswerdlow/received_events",
"repos_url": "https://api.github.com/users/alexanderswerdlow/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alexanderswerdlow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexanderswerdlow/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alexanderswerdlow"
} | https://api.github.com/repos/huggingface/datasets/issues/7080/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7080/timeline | open | false | 7,080 | null | null | null | false |
2,433,363,298 | https://api.github.com/repos/huggingface/datasets/issues/7079 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7079/events | [] | null | 2024-07-27T20:06:44Z | [] | https://github.com/huggingface/datasets/issues/7079 | NONE | completed | null | null | [
"same issue here. @albertvillanova @lhoestq ",
"Also impacted by this issue in many of my datasets (though not all) - in my case, this also seems to affect datasets that have been updated recently. Git cloning and the web interface still work:\r\n- https://huggingface.co/api/datasets/acmc/cheat_reduced\r\n- https... | HfHubHTTPError: 500 Server Error: Internal Server Error for url: | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7079/reactions"
} | I_kwDODunzps6RCi1i | null | 2024-07-27T08:21:03Z | https://api.github.com/repos/huggingface/datasets/issues/7079/comments | ### Describe the bug
newly uploaded datasets, since yesterday, yields an error.
old datasets, works fine.
Seems like the datasets api server returns a 500
I'm getting the same error, when I invoke `load_dataset` with my dataset.
Long discussion about it here, but I'm not sure anyone from huggingface have seen it.
https://discuss.huggingface.co/t/hfhubhttperror-500-server-error-internal-server-error-for-url/99580/1
### Steps to reproduce the bug
this api url:
https://huggingface.co/api/datasets/neoneye/simon-arc-shape-v4-rev3
respond with:
```
{"error":"Internal Error - We're working hard to fix this as soon as possible!"}
```
### Expected behavior
return no error with newer datasets.
With older datasets I can load the datasets fine.
### Environment info
# Browser
When I access the api in the browser:
https://huggingface.co/api/datasets/neoneye/simon-arc-shape-v4-rev3
```
{"error":"Internal Error - We're working hard to fix this as soon as possible!"}
```
### Request headers
```
Accept text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Encoding gzip, deflate, br, zstd
Accept-Language en-US,en;q=0.5
Connection keep-alive
Host huggingface.co
Priority u=1
Sec-Fetch-Dest document
Sec-Fetch-Mode navigate
Sec-Fetch-Site cross-site
Upgrade-Insecure-Requests 1
User-Agent Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:127.0) Gecko/20100101 Firefox/127.0
```
### Response headers
```
X-Firefox-Spdy h2
access-control-allow-origin https://huggingface.co
access-control-expose-headers X-Repo-Commit,X-Request-Id,X-Error-Code,X-Error-Message,X-Total-Count,ETag,Link,Accept-Ranges,Content-Range
content-length 80
content-type application/json; charset=utf-8
cross-origin-opener-policy same-origin
date Fri, 26 Jul 2024 19:09:45 GMT
etag W/"50-9qrwU+BNI4SD0Fe32p/nofkmv0c"
referrer-policy strict-origin-when-cross-origin
vary Origin
via 1.1 1624c79cd07e6098196697a6a7907e4a.cloudfront.net (CloudFront)
x-amz-cf-id SP8E7n5qRaP6i9c9G83dNAiOzJBU4GXSrDRAcVNTomY895K35H0nJQ==
x-amz-cf-pop CPH50-C1
x-cache Error from cloudfront
x-error-message Internal Error - We're working hard to fix this as soon as possible!
x-powered-by huggingface-moon
x-request-id Root=1-66a3f479-026417465ef42f49349fdca1
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/147971?v=4",
"events_url": "https://api.github.com/users/neoneye/events{/privacy}",
"followers_url": "https://api.github.com/users/neoneye/followers",
"following_url": "https://api.github.com/users/neoneye/following{/other_user}",
"gists_url": "https://api.github.com/users/neoneye/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/neoneye",
"id": 147971,
"login": "neoneye",
"node_id": "MDQ6VXNlcjE0Nzk3MQ==",
"organizations_url": "https://api.github.com/users/neoneye/orgs",
"received_events_url": "https://api.github.com/users/neoneye/received_events",
"repos_url": "https://api.github.com/users/neoneye/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/neoneye/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neoneye/subscriptions",
"type": "User",
"url": "https://api.github.com/users/neoneye"
} | https://api.github.com/repos/huggingface/datasets/issues/7079/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7079/timeline | closed | false | 7,079 | null | 2024-07-27T19:52:30Z | null | false |
End of preview. Expand
in Data Studio
README.md exists but content is empty.
- Downloads last month
- 5