
Proactive-Interactive-R1/Proactive-Interactive-R1-Math-7B-Max
8B • Updated • 2
None defined yet.
![]()
This organization hosts the official models and datasets for the paper "Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers".
Current reasoning LLMs (e.g., GPT-o1, DeepSeek-R1) suffer from blind self-thinking: they perform extensive internal reasoning even when critical information is missing or user intent is ambiguous. This leads to overthinking, hallucinations, and misaligned conclusions.
PIR (Proactive Interactive Reasoning) is a new paradigm that transforms reasoning LLMs from passive solvers into proactive inquirers. Instead of guessing, PIR-enabled models detect uncertainty during reasoning and actively ask users for clarification before proceeding.
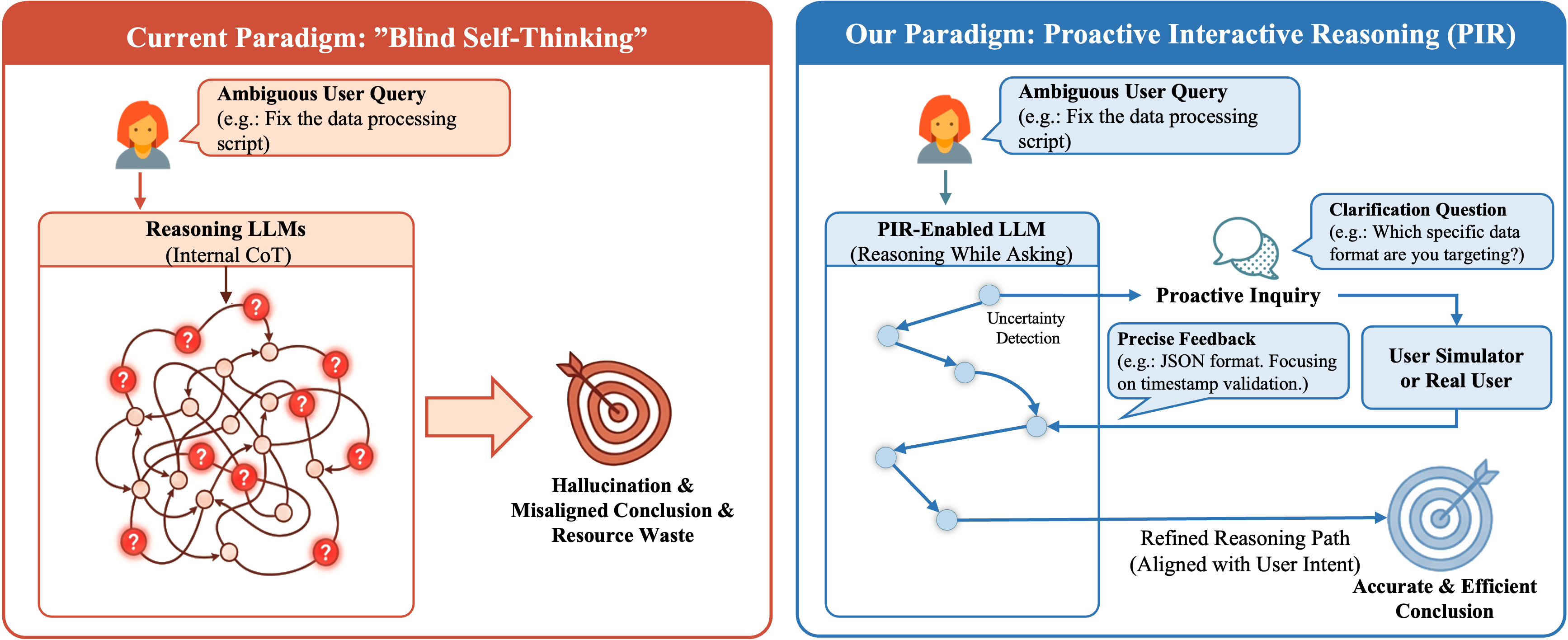
We provide the following models trained with the PIR paradigm:
| Model Name | Description | Link |
|---|---|---|
| Proactive-Interactive-R1-Math-7B | The core model optimized for mathematical reasoning with clarification capabilities. | View Model |
| Proactive-Interactive-R1-Math-7B-Pro | An enhanced version of the Math-7B model. | View Model |
| Proactive-Interactive-R1-SFT-7B | The base SFT model before Reinforcement Learning alignment. | View Model |
The datasets used to train and evaluate PIR are available here:
If you find this work useful, please cite our paper:
@misc{chen2026reasoningaskingtransformingreasoning,
title={Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers},
author={Xin Chen and Feng Jiang and Yiqian Zhang and Hardy Chen and Shuo Yan and Wenya Xie and Min Yang and Shujian Huang},
year={2026},
eprint={2601.22139},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2601.22139},
}