|
|
--- |
|
|
license: mit |
|
|
datasets: |
|
|
- FreedomIntelligence/Huatuo26M-Lite |
|
|
- CocoNutZENG/NeuroQABenchmark |
|
|
language: |
|
|
- zh |
|
|
- en |
|
|
metrics: |
|
|
- accuracy |
|
|
base_model: |
|
|
- Qwen/Qwen2.5-7B-Instruct |
|
|
tags: |
|
|
- medical |
|
|
pipeline_tag: text-generation |
|
|
library_name: peft |
|
|
--- |
|
|
## Introduction |
|
|
Train LLM to be neuroscientist. It expected to work in Chinese and Engliah environment. |
|
|
|
|
|
## Data |
|
|
1. [FreedomIntelligence/Huatuo26M-Lite](https://huggingface.co/datasets/FreedomIntelligence/Huatuo26M-Lite). We select neuroscience(神经科学) label as train data. |
|
|
2. [CocoNutZENG/NeuroQABenchmark](https://huggingface.co/datasets/CocoNutZENG/NeuroQABenchmark) |
|
|
|
|
|
|
|
|
## Train Detail |
|
|
We fine-tuned the Qwen2.5 model using supervised fine-tuning (SFT) with LoRA for efficient parameter optimization. The LoRA configuration employed a rank of 8 (R=8) to |
|
|
balance adaptation quality with computational efficiency. Training was conducted for 1 epoch (approximately 1 hour duration) using two NVIDIA A40 GPUs with DeepSpeed’s Stage 2 optimization |
|
|
for memory efficiency. We adopted the Adam optimizer with an initial learning rate of 5e-5 and a |
|
|
cosine learning rate scheduler for smooth decay. This configuration achieved effective model adaptation while maintaining computational tractability on our hardware setup. Our model’s loss drop as |
|
|
expected, see figure below for loss detail. |
|
|
[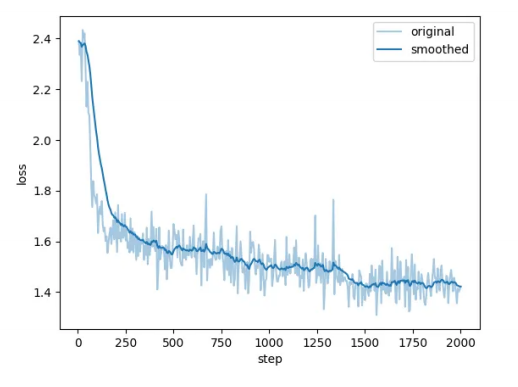](https://postimg.cc/62FPnJzF) |
|
|
|
|
|
## Evalution |
|
|
| Model | Acc | |
|
|
|----------------|-------| |
|
|
| Qwen2.5-3b | 0.788 | |
|
|
| Qwen2.5-7b | 0.820 | |
|
|
| +HuatuoLite | 0.832 | |
|
|
| +Full data | 0.848 | |
