


Commit
·
ab2409c
verified
·
0
Parent(s):
Duplicate from Query-of-CC/Knowledge_Pile
Browse filesCo-authored-by: Zhaoye Fei <ngc7293@users.noreply.huggingface.co>
- .gitattributes +60 -0
- README.md +57 -0
- data/part-65c38103819a-000496.jsonl +3 -0
- data/part-65c38103819a-000733.jsonl +3 -0
- data/part-65c38103819a-001897.jsonl +3 -0
- data/part-65c38103819a-003777.jsonl +3 -0
- data/part-65c38103819a-004739.jsonl +3 -0
.gitattributes
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.lz4 filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
# Audio files - uncompressed
|
| 38 |
+
*.pcm filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
*.sam filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
*.raw filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
# Audio files - compressed
|
| 42 |
+
*.aac filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
*.flac filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
*.mp3 filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
*.ogg filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
*.wav filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
# Image files - uncompressed
|
| 48 |
+
*.bmp filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
*.gif filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
*.tiff filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
# Image files - compressed
|
| 53 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
*.webp filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
data/part-65c38103819a-000496.jsonl filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
data/part-65c38103819a-000733.jsonl filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
data/part-65c38103819a-001897.jsonl filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
data/part-65c38103819a-003777.jsonl filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
data/part-65c38103819a-004739.jsonl filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
tags:
|
| 6 |
+
- knowledge
|
| 7 |
+
- Retrieval
|
| 8 |
+
- Reasoning
|
| 9 |
+
- Common Crawl
|
| 10 |
+
- MATH
|
| 11 |
+
size_categories:
|
| 12 |
+
- 100B<n<1T
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
Knowledge Pile is a knowledge-related data leveraging [Query of CC](https://arxiv.org/abs/2401.14624).
|
| 16 |
+
|
| 17 |
+
This dataset is a partial of Knowledge Pile(about 40GB disk size), full datasets have been released in [\[🤗 knowledge_pile_full\]](https://huggingface.co/datasets/Query-of-CC/knowledge_pile_full/), a total of 735GB disk size and 188B tokens (using Llama2 tokenizer).
|
| 18 |
+
|
| 19 |
+
## *Query of CC*
|
| 20 |
+
|
| 21 |
+
Just like the figure below, we initially collected seed information in some specific domains, such as keywords, frequently asked questions, and textbooks, to serve as inputs for the Query Bootstrapping stage. Leveraging the great generalization capability of large language models, we can effortlessly expand the initial seed information and extend it to an amount of domain-relevant queries. Inspiration from Self-instruct and WizardLM, we encompassed two stages of expansion, namely **Question Extension** and **Thought Generation**, which respectively extend the queries in terms of breadth and depth, for retrieving the domain-related data with a broader scope and deeper thought. Subsequently, based on the queries, we retrieved relevant documents from public corpora, and after performing operations such as duplicate data removal and filtering, we formed the final training dataset.
|
| 22 |
+
|
| 23 |
+
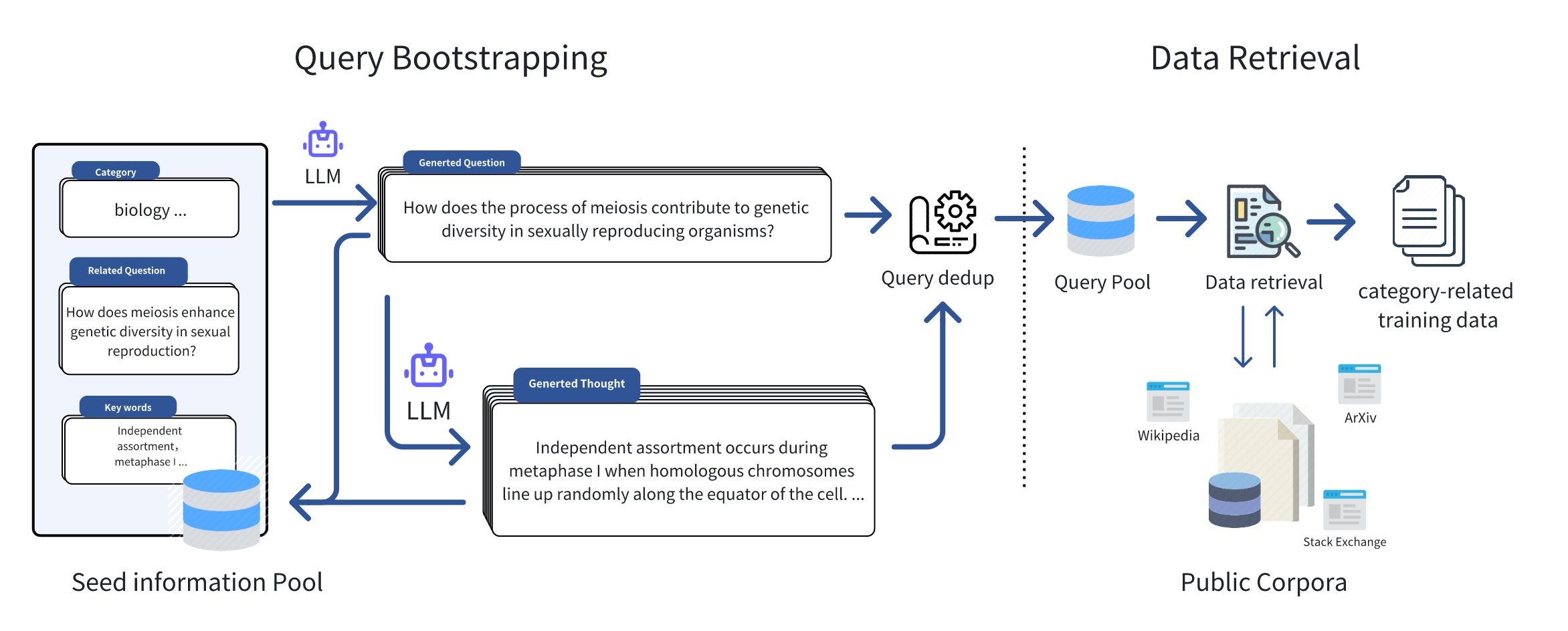
|
| 24 |
+
|
| 25 |
+
## **Knowledge Pile** Statistics
|
| 26 |
+
|
| 27 |
+
Based on *Query of CC* , we have formed a high-quality knowledge dataset **Knowledge Pile**. As shown in Figure below, comparing with other datasets in academic and mathematical reasoning domains, we have acquired a large-scale, high-quality knowledge dataset at a lower cost, without the need for manual intervention. Through automated query bootstrapping, we efficiently capture the information about the seed query. **Knowledge Pile** not only covers mathematical reasoning data but also encompasses rich knowledge-oriented corpora spanning various fields such as biology, physics, etc., enhancing its comprehensive research and application potential.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
<img src="https://github.com/ngc7292/query_of_cc/blob/master/images/query_of_cc_timestamp_prop.png?raw=true" width="300px" style="center"/>
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
This table presents the top 10 web domains with the highest proportion of **Knowledge Pile**, primarily including academic websites, high-quality forums, and some knowledge domain sites. Table provides a breakdown of the data sources' timestamps in **Knowledge Pile**, with statistics conducted on an annual basis. It is evident that a significant portion of **Knowledge Pile** is sourced from recent years, with a decreasing proportion for earlier timestamps. This trend can be attributed to the exponential growth of internet data and the inherent timeliness introduced by the **Knowledge Pile**.
|
| 34 |
+
|
| 35 |
+
| **Web Domain** | **Count** |
|
| 36 |
+
|----------------------------|----------------|
|
| 37 |
+
|en.wikipedia.org | 398833 |
|
| 38 |
+
|www.semanticscholar.org | 141268 |
|
| 39 |
+
|slideplayer.com | 108177 |
|
| 40 |
+
|www.ncbi.nlm.nih.gov | 97009 |
|
| 41 |
+
|link.springer.com | 85357 |
|
| 42 |
+
|www.ipl.org | 84084 |
|
| 43 |
+
|pubmed.ncbi.nlm.nih.gov | 68934 |
|
| 44 |
+
|www.reference.com | 61658 |
|
| 45 |
+
|www.bartleby.com | 60097 |
|
| 46 |
+
|quizlet.com | 56752 |
|
| 47 |
+
|
| 48 |
+
### cite
|
| 49 |
+
|
| 50 |
+
```
|
| 51 |
+
@article{fei2024query,
|
| 52 |
+
title={Query of CC: Unearthing Large Scale Domain-Specific Knowledge from Public Corpora},
|
| 53 |
+
author={Fei, Zhaoye and Shao, Yunfan and Li, Linyang and Zeng, Zhiyuan and Yan, Hang and Qiu, Xipeng and Lin, Dahua},
|
| 54 |
+
journal={arXiv preprint arXiv:2401.14624},
|
| 55 |
+
year={2024}
|
| 56 |
+
}
|
| 57 |
+
```
|
data/part-65c38103819a-000496.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cab2f90d01ed1cc2f55ffe5b3eccf5afe794bae9dee5c7b73ea9ecdb0ff1b0f3
|
| 3 |
+
size 8441619960
|
data/part-65c38103819a-000733.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:df0b02c670f82658b320bcb2143c02b09b48cbeb0db194d58ff51ae2296a86c1
|
| 3 |
+
size 8459325496
|
data/part-65c38103819a-001897.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ee5c8889c57e9b839857168f09372d54f8deead9cc6de084ffba36527f70dc98
|
| 3 |
+
size 8425393120
|
data/part-65c38103819a-003777.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dfab62618c7c173454b3d1dc5c0b24e085a84d18bff5c92f4ff9b839b6e2edb7
|
| 3 |
+
size 8420352269
|
data/part-65c38103819a-004739.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3e6d6240f571faf83522241db902a5c080d6c8f479d20515549b14908ec93792
|
| 3 |
+
size 8428879526
|